

Alibaba a présenté son plus grand modèle d'IA, avec un milliard de paramètres. La question est de savoir si à ce stade cela signifie quelque chose
Le géant chinois Alibaba a annoncé un nouveau modèle de langue, le plus grand qu'ils ont annoncé à ce jour. Il est appelé QWEN-3-MAX et présume qu'il a plus d'un milliard de paramètres.
Le plus grand. Il s'agit du dernier modèle de la série Qwen3 qui a été lancé en mai de cette année et, comme son nom «Max» l'indique, il est le plus grand à ce jour. Sa taille est donnée par les paramètres, 1 milliard pour être exact, tandis que les modèles précédents de sa série ont atteint un maximum de 235 000 millions. Selon South China Morning Post (qui possède Alibaba), son modèle se démarque dans la compréhension du langage, du raisonnement et de la génération de texte.
Benchmarks. Les résultats des repères placent Qwen3-Max devant les concurrents tels que Claude Opus 4, Deepseek V3.1 et Kimi K2. Si Gemini 2.5 Pro ou GPT-5 n'apparaît pas, c'est parce qu'ils sont des modèles de raisonnement et n'ont comparé que des modèles de réponse rapide. Comme indiqué dans Dev.T.T., Gemini 2.5 Pro et GPT-5 obtiennent des scores plus élevés en mathématiques et en code, de sorte que les modèles de raisonnement continuent d'avoir un avantage dans ces domaines. Qwen3-max-preview peut déjà être testé gratuitement.
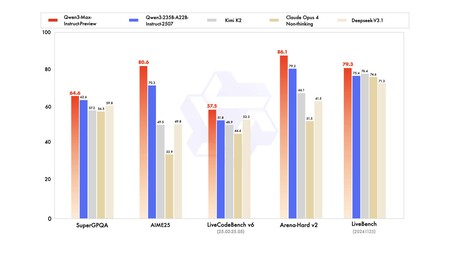
Benchmarks partagés par Alibaba.
Paramètres Les paramètres sont toutes les variables internes qu'un modèle apprend pendant la formation. En d'autres termes, il est de savoir que le modèle a obtenu à partir des données avec lesquelles il a formé et lui permet d'interpréter nos demandes et de générer leurs réponses. En théorie, plus les paramètres auront des capacités plus et meilleures. Cela implique également qu'il a besoin de plus de puissance de calcul à la fois pour s'entraîner et pour exécuter le modèle.
Plus ne signifie pas mieux. Le discours des paramètres se souvient de celui des mégapixels avec les premières caméras. Un capteur de 100 mégapixels prendra des photos plus grandes qu'un capteur 10, mais il existe d'autres facteurs cruciaux qui affectent la qualité de l'image tels que la taille du capteur ou la luminosité de l'objectif.
Données de qualité. Plus de paramètres peuvent être traduits en plus de capacité d'apprentissage et plus de résolution des tâches complexes, tant que des données de formation de qualité ont été utilisées. Il est évident: un modèle de langue qui a été formé avec des données redondantes, incorrectes ou biaisées apprendra et continuera de reproduire ces erreurs dans leur opération.
Il y en a plus. En 2022, le laboratoire DeepMind de Google a découvert que de nombreux modèles étaient surdimensionnés dans les paramètres mais soulignés dans les données. Pour le démontrer, ils ont créé le modèle Chinchilla avec « seulement » 70 000 millions de paramètres, mais quatre fois plus de données. Le résultat a été qu'il a battu Gopher, un modèle avec quatre fois plus de paramètres.
Architecture. L'architecture du modèle est un autre facteur décisif pour atteindre un modèle efficace; Une architecture standard n'est pas la même qui oblige le modèle à utiliser tout son réseau neuronal, qu'un mélange comme des experts qui se compose de nombreux réseaux plus petits. Ce serait quelque chose comme avoir un comité d'experts chacun avec une spécialité. De cette façon, le modèle peut choisir votre expert pour chaque requête et ne pas avoir à utiliser l'ensemble du réseau. Par exemple, avec cette technique, Mistral parvient à utiliser seulement une fraction de ses paramètres et il est donc plus rapide et moins cher à exécuter.
Image | Markus Winkler, via Pexels
Dans Simseo | L'alliance ASML-Mistral révèle le plan européen B: Si nous ne pouvons pas fabriquer de copeaux, nous contrôlerons au moins comment ils sont fabriqués