
Vers un nouveau cadre pour accélérer l'inférence du modèle de langue importante
Une sortie de haute qualité à faible latence est une exigence critique lors de l'utilisation de modèles de langage grand (LLM), en particulier dans les scénarios du monde réel, tels que les chatbots interagissant avec les clients, ou les assistants de code IA utilisés par des millions d'utilisateurs par jour.
Actuellement, les LLM utilisent un framework appelé décodage autorégressif, dans lequel le texte est généré un jeton à la fois, et le texte précédent est utilisé pour générer la séquence suivante. Cependant, cela est clairement inefficace, car pour des séquences plus longues, le temps de générer des réponses augmente linéairement.
Pour résoudre ce problème, les chercheurs explorent largement l'utilisation du décodage spéculatif qui suit un cadre « Guess and Verify ». Dans cette approche, un LLM plus petit spécifiquement formé devine plusieurs jetons de texte à l'avance, qui est simultanément vérifié par le LLM d'origine, réduisant considérablement le temps de génération de réponse.
Mais ces approches nécessitent une formation de modèle supplémentaire et des ressources informatiques étendues. Alors que les chercheurs ont considéré les modèles spéculatifs sans formation en parallèle, le gain d'accélération dans ces approches reste limité en raison d'une qualité réduite de leurs suppositions spéculatives.
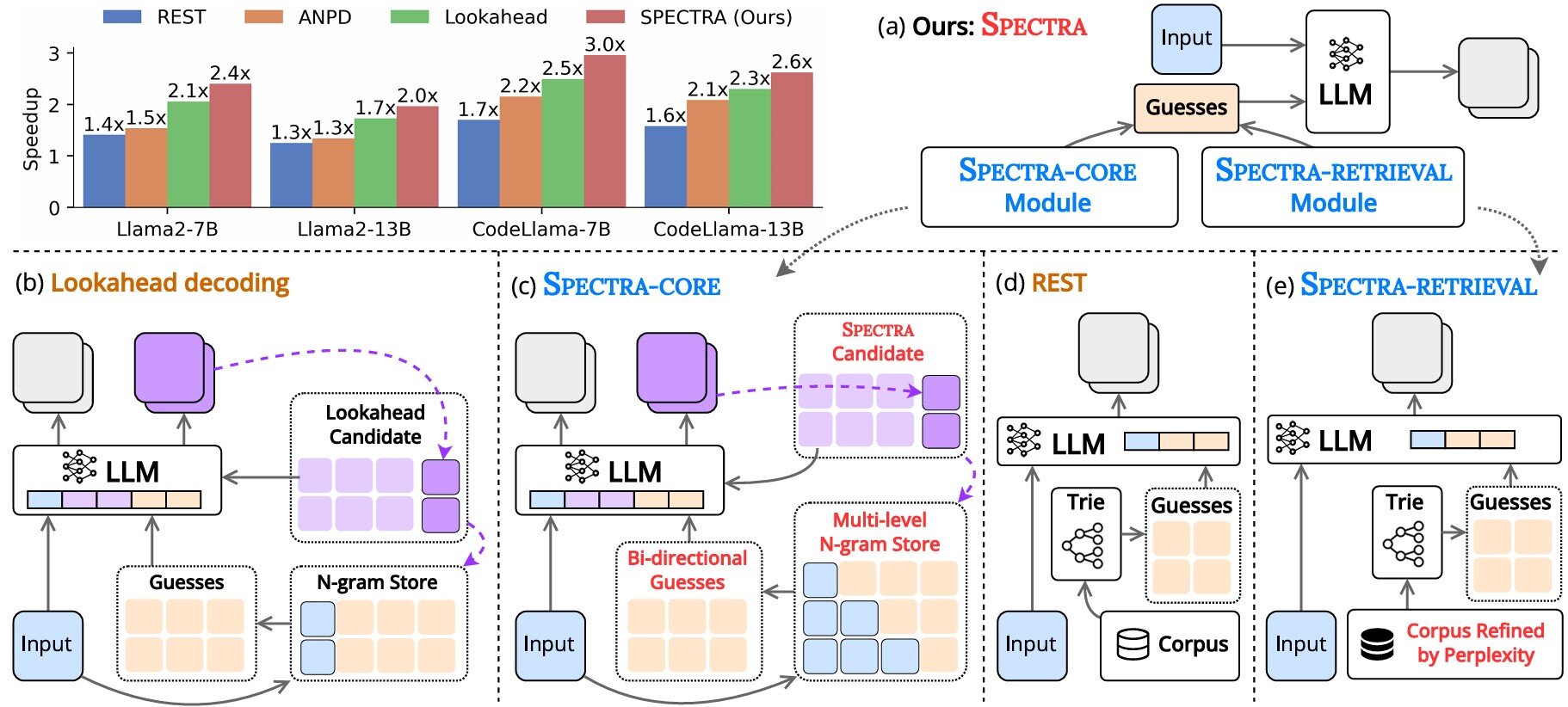
Pour combler ces lacunes dans le domaine, le professeur Nguyen Le Minh et ses doctorants, Nguyen-Khang Le et Dinh-Truong Do, du Japon Advanced Institute of Science and Technology (JAIST) ont récemment développé un nouveau cadre de décodage spéculatif appelé Spectra et une vitesse de génération de texte accélérée démontrée sans avoir besoin d'une formation supplémentaire.
« Le cadre se compose de deux composants principaux: un module de base (spectra-core), qui intègre de manière transparente dans les LLM de manière plug-and-play, et un module de récupération facultatif (spectre-rétrival) qui améliore encore les performances », explique le professeur Nguyen. Les conclusions de l'équipe ont été présentées lors de la 63e réunion annuelle de l'Association for Computational Linguistics (ACL 2025) par Dinh-Truong Truong et sont publiées dans la procédure de conférence.
Spectra-core, le module de base, génère des suppositions de haute qualité en utilisant le modèle de distribution de texte prévu par le LLM, améliorant le décodage spéculatif. Dans ce système intelligent, les dictionnaires contenant différentes tailles de séquences de mots (n-grammes) peuvent être recherchés bidirectionnellement (vers l'avant et vers l'arrière) pour prédire les combinaisons de mots, en devinant les phrases de longueurs variables rapidement et plus précisément. De plus, Spectra continue d'optimiser les dictionnaires N-Gram en les mettant constamment à les mettre à jour avec de nouvelles combinaisons de mots, en assurant une couverture texte robuste.
Pour accélérer les choses davantage, le module de récupération, le spectra-rétrival, est intégré dans les spectres-core. Les approches existantes qui utilisent des sources externes pour récupérer des informations et générer des suppositions dans le décodage spéculatif ont souvent du mal à s'intégrer à d'autres cadres de décodage, car le temps de recherche dépasse les résultats d'accélération.
En revanche, le spectre filtre un grand ensemble de données de textes et ne tient que les pièces qui sont faciles à prédire pour la LLM cible sur la base des scores de perplexité. Ceci, à son tour, garantit que seules des données pertinentes de haute qualité sont utilisées pour la formation ou le réglage fin du modèle, permettant une intégration transparente avec des spectres-core.
Dans leur étude, l'équipe a testé des spectres sur six tâches, notamment des conversations multiples, une génération de code et un raisonnement mathématique, dans trois familles LLM – Llama 2, Llama 3 et Codellama. Les spectres ont obtenu des gains de mise à l'accélération 4x et ont pu surpasser les méthodes de décodage spéculatif non-traçage de pointe, notamment REST, ANPD et Lookahead.
Bien que l'architecture globale de l'architecture et les caractéristiques de l'ensemble de données aient déterminé les gains d'accélération des méthodes de décodage spéculatives, les spectres ont montré une fiabilité à travers une gamme de modèles et d'ensembles de données, accélérant systématiquement les rapports d'accélération.
« En intégrant notre module de spectres de plug-and-play-play – qui tire parti de la recherche de stockage et de recherche bidirectionnelle à plusieurs niveaux – avec le module raffiné du spectre, nous avons pu réaliser des accéléreuses substantielles (jusqu'à 4,08 ×) de la qualité de la puissance de la perplexité et des architectures du modèle. Nguyen.
En réduisant le temps de génération de réponse sans avoir besoin de recycler les LLM, Spectres offre une solution pratique pour les systèmes commerciaux et de recherche qui utilisent des LLM et pourraient très bien conduire à une amélioration de l'accessibilité et de la durabilité des AIS à haute performance à long terme.