

J'ai un chatpt à la maison
Pouvoir utiliser Chatgpt dans le cloud est fantastique. Il est toujours là, disponible, en se souvenant de nos chats précédents et en répondant rapidement et efficacement. Mais en fonction de ce service, des inconvénients ont également des inconvénients (coût, confidentialité), et c'est là qu'une possibilité fantastique entre: exécuter les modèles d'IA locaux. Par exemple, configurez un Chatpt local.
C'est ce que nous avons pu vérifier à Simseo lors de la récession des nouveaux modèles Openai Open. Dans notre cas, nous voulions essayer le modèle GPT-ASS-20B, qui peut être utilisé théoriquement sans trop de problèmes avec 16 Go de mémoire.
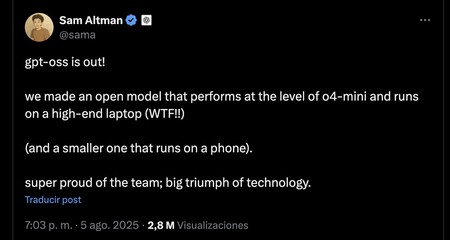
C'est au moins ce que Sam Altman a présumé hier, qui après le lancement a affirmé que le modèle supérieur (120b) peut être exécuté dans un ordinateur portable élevé, tandis que le plus petit peut être exécuté sur un mobile.
Notre expérience, qui est allée à Trompcon, confirme ces mots.
Premiers tests: échec
Après avoir essayé le modèle pendant quelques heures, il m'a semblé que cette déclaration était exagérée. Mes tests étaient simples: j'ai un Mac Mini M4 avec 16 Go de mémoire unifiée, et je teste des modèles d'IA depuis des mois via Olllama, une application qui le rend particulièrement facile à télécharger et à les exécuter à la maison.
Dans ce cas, le processus pour prouver que le nouveau « petit » modèle d'Openai était simple:
- Installez Olllama dans mon Mac (je l'ai déjà fait installer)
- Terme un terminal en macOS
- Téléchargez et exécutez le modèle OpenAI avec une commande simple: «
Ce faisant, l'outil commence à télécharger le modèle, qui pèse environ 13 Go, se poursuit déjà. Jetez-le pour pouvoir l'utiliser déjà un peu: il est nécessaire de déplacer ces 13 Go du modèle et de les passer du disque à la mémoire unifiée du Mac. Après une ou deux minutes, l'indicateur apparaît que vous pouvez déjà écrire et discuter avec GPT-OSS-20B.
C'est à ce moment-là que j'ai commencé à essayer de demander certaines choses, comme ce test traditionnel de dire aux erre. Ainsi, j'ai commencé à demander au modèle de me répondre à la question « combien de » r « y a-t-il dans l'expression » Le chien de San Roque n'a pas de queue parce que Ramón Ramírez l'a coupé? «

Là, GPT-OSS-20B a commencé à « penser » et a montré sa chaîne de pensée (chaîne de pensée) dans une couleur plus gris. Ce faisant, on découvre que, en effet, ce modèle a parfaitement répondu à la question, et se séparait par des mots, puis se casse dans chaque mot pour savoir combien d'erreurs il y avait dans chacun. Il les a ajoutés à la fin et a obtenu le résultat correct.
Le problème? C'était lent. Très lent.
Non seulement cela: dans la première exécution de ce modèle, deux instances de Firefox s'étaient ouvertes avec environ 15 onglets chacun, en plus d'une session Slack dans MacOS. C'était un problème, car GPT-OSS-20B a besoin d'au moins 13 Go de RAM, et Firefox et Slack et les services de fond eux-mêmes consomment déjà beaucoup.
Cela a fait de l'essayer de l'utiliser, le système d'effondrement. Soudain, mon Mac Mini M4 avec 16 Go de mémoire unifiée a été complètement suspendu, sans répondre à aucun mouvement de support ou de souris. J'étais mort, donc j'ai dû le redémarrer aux durs. Dans le redémarrage suivant, j'ai simplement ouvert le terminal pour exécuter Olllama, et dans ce cas, je pouvais utiliser le modèle GPT-OSS-20B, bien que comme je le dis, limité par la lenteur des réponses.
Cela a provoqué que de nombreuses autres preuves pourraient se produire non plus. J'ai essayé de commencer une conversation sans importance, mais là j'ai fait une erreur: ce modèle est un modèle de raisonnement, et essaie donc de répondre toujours mieux qu'un modèle qui ne raisonne pas, mais cela implique qu'il faut encore plus pour répondre et consommer plus de ressources. Et dans une équipe comme celle-ci, qui commence déjà, c'est un problème.
En fin de compte, le succès total
Après avoir commenté l'expérience dans X quelques messages dans X, j'ai été encouragé à réessayer, mais cette fois avec LM Studio, qui offre directement une interface beaucoup plus graphique en ligne avec laquelle Chatgpt offre dans le navigateur.
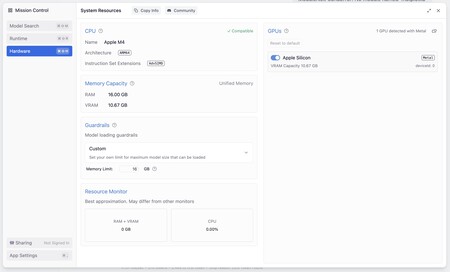
Sur les 16 Go de mémoire unifiée de mon Mac Mini M4, LM Studio indique que 10.67 sont dédiés à la mémoire graphique dès maintenant. Ces données étaient essentielles pour utiliser le modèle ouvert d'Openai sans problème.
Après l'avoir installé et téléchargé le modèle, je me suis préparé à l'essayer, mais quand je l'ai essayé, je me suis donné une erreur en disant que je n'avais pas assez de ressources pour démarrer le modèle. Le problème: la mémoire graphique attribuée, qui était insuffisante.
Lors de la navigation dans la configuration de l'application, j'ai prouvé que la mémoire graphique unifiée avait été distribuée de manière spéciale, en attribuant dans cette session 10,67 Go à la mémoire graphique.
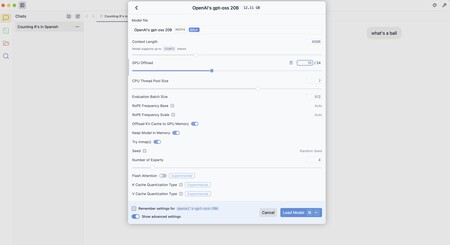
La clé consiste à «éclairer» l'exécution du modèle. Pour cela, il est possible de réduire le niveau de «déchargement du GPU» – combien de couches du modèle sont chargées dans le GPU. Plus nous chargeons plus rapidement, mais aussi plus de mémoire graphique consomment. La localisation de cette limite en 10, par exemple, était une bonne option.
Il existe d'autres options telles que la désactivation de « décharger le cache KV à la mémoire du GPU » (résultats intermédiaires de Cachea) ou réduire la « taille du lot d'évaluation », combien de jeton sont traités en parallèle, que nous pouvons télécharger de 512 à 256 ou même 128.
Une fois ces paramètres établis, j'ai finalement obtenu le modèle en mémoire (cela prend quelques secondes) et je peux l'utiliser. Et là, la chose a changé, parce que j'ai trouvé un Chatgpt plus que décent qui a répondu assez rapidement aux questions et c'était, en substance, très utilisable.
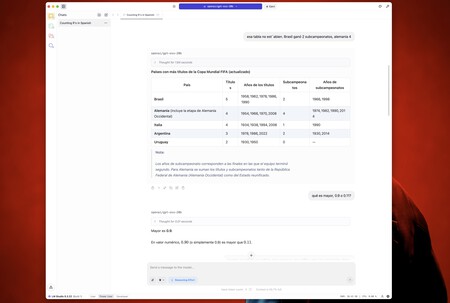
Ainsi, je lui ai posé des questions sur le problème des erre (il a répondu parfaitement), puis j'ai également demandé qu'il avait fait une table avec les cinq pays que la plupart des championnats et des coureurs – dans le monde du football ont gagné.
Ce test est relativement simple – les données correctes sont sur Wikipedia – mais les IAS sont erronées et encore une fois et cela ne faisait pas exception. Certaines années ont été inventées pour certains pays et ont changé le nombre de coureurs, même lorsque je lui ai demandé de revoir les informations.
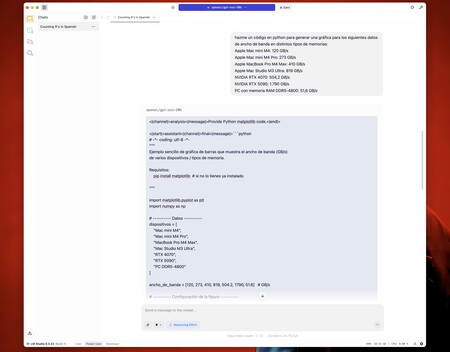
Ensuite, je voulais essayer quelque chose de différent: générer un petit code dans Python pour créer un graphique à partir de certaines données de démarrage. Il m'a dit que je devais installer une librairie (Matplotlib), puis générer le code du graphique.
Il convient de noter que cette version de « Chatpt local » ne génère pas d'images, mais elle peut créer du code qui génère des graphiques, par exemple, et c'est ce que j'ai fait. Après avoir exécuté ce code dans le terminal, surprise. Comme vous le verrez plus tard, le résultat, bien que quelque peu brut, est sordide (et correct).
La vérité est que les performances du modèle d'IA local m'ont surpris très agréablement. Il est vrai que vous pouvez faire des erreurs, mais comme les ingénieurs Openai le promettent, les performances sont très similaires à celles du modèle O3-Mini qui est toujours une excellente option même lorsque vous l'utilisez dans le cloud.
Les réponses sont généralement vraiment décentes en précision, et les échecs que vous pouvez avoir et ce que nous avons vu – les tests se sont limités à quelques heures – sont conformes aux autres modèles de dernière génération qui sont encore plus avancés et exigeants en ressources. Ainsi, plus qu'une agréable surprise dans ces premières impressions.
La mémoire est tout
Le problème initial avec nos preuves révèle une réalité: la déclaration d'Openai et Sam Altman ont une petite impression. L'annonce parle de deux variantes de leurs modèles ouverts de l'IA. Le premier, avec 120 000 millions de paramètres (120b) et le second avec 20 000 millions (20b). Les deux peuvent être téléchargés et utilisés gratuitement, mais comme nous l'avons indiqué, il existe certaines exigences matérielles pour le faire.
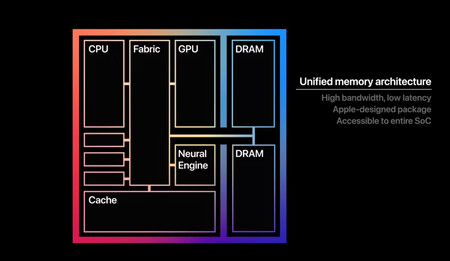
Les puces Apple unifiées sont devenues son grand avantage lors de l'exécution de modèles d'IA locaux. Source: Apple.
Ainsi, pour pouvoir exécuter ces modèles dans nos équipes, nous aurons surtout besoin d'une certaine quantité de mémoire:
- GPT-OSS-120B: au moins 80 Go de mémoire
- GPT-OSS-20B: au moins 16 Go de mémoire
Et ici, le détail critique est que ces 80 Go ou 16 Go de mémoire devraient être prudents avec cela, par mémoire graphique. Ou ce qui est la même chose: pour pouvoir les utiliser facilement, nous aurons au moins besoin de cette quantité de mémoire dans notre GPU dédié ou intégré.
Alors que les PC utilisent la RAM d'un côté et la mémoire graphique (dans le GPU, beaucoup plus rapidement) de l'autre, les Mac Apple font que la mémoire unifiée utilise. Autrement dit, ils «combinent» les deux types et «unify» pour utiliser cette mémoire de manière interchangeable comme mémoire principale ou comme mémoire graphique.
Cette mémoire unifiée a une performance qui est à cheval entre le RAM conventionnel utilisé sur les PC Windows et celui qui est présent dans les cartes graphiques de dernière génération.
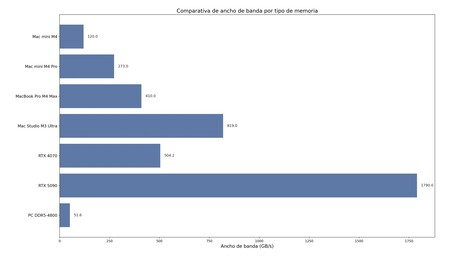
Bande passante de différents types de systèmes de mémoire. Le graphique a été généré via un petit code dans Python généré par GPT-OSS-20B.
Pour avoir une idée, la bande passante de certaines puces Apple (avec des systèmes de mémoire unifiée similaires, mais de plus en plus puissants selon la puce) et RAM Memories and Conventional Graphics est approximativement la suivante:
- Apple Mac Mini M4: 120 Go / s (1)
- Apple Mac Mini M4 Pro: 273 Go / s (1)
- Apple MacBook Pro M4 Max: 410 Go / s (2)
- Apple Mac Studio M3 Ultra: 819 Go / s (3)
- Nvidia RTX 4070: 504,2 Go / s (4)
- Nvidia RTX 5090: 1 790 Go / s (5)
- PC avec RAM DDR5-4800: 51,6 Go / s (6)
Comme on peut le voir, dans un PC actuel, la RAM est beaucoup plus lente que dans les puces Apple les plus avancées. Le Mac Mini M4 que j'ai utilisé dans les tests n'est pas particulièrement remarquable, mais la bande passante de sa mémoire est double de celle des modules DDR5-4800. Ici, en passant, c'est là que nous avons mentionné ci-dessus, nous avons utilisé notre « Chatgpt local » pour générer un graphique à partir d'un petit code de Python. Le résultat, sans être particulièrement coloré, est fonctionnel et correct.
En fin de compte, l'idée après le graphique est précisément pour refléter la chose la plus importante lors de l'exécution de modèles d'IA locaux. Le GPU et le NPU aident certainement beaucoup, mais la clé est dans 1) la quantité de mémoire graphique que nous avons et 2) quelle bande passante cette mémoire graphique a-t-elle. Et dans les deux cas, plus, beaucoup mieux, surtout si nous voulons exécuter des modèles lourds à la maison, ce qui peut laisser très, très cher.
Le modèle GPT-OS-120B, par exemple, nécessiterait au moins 80 Go de mémoire graphique, et il n'y a pas beaucoup d'équipes qui peuvent se vanter de quelque chose comme ceci: ici, le schéma de mémoire Apple unifié est une option pour l'instant gagnant, car l'alternative est d'utiliser un ou plusieurs graphiques haut de gamme dédiés pour utiliser des modèles locaux avec des fenêtres basse ou une facilité de Linux.
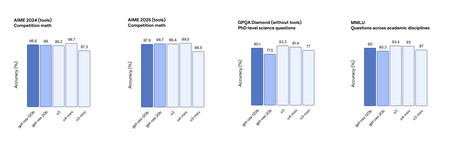
Diverses repères révèlent que ces modèles ouverts sont au niveau de O3-MinI et non loin de O4-MINI dans certains tests. Source: Openai.
Cela dit, il sera intéressant de voir où ces modèles finissent par bouger. L'énoncé selon lequel le plus petit modèle (GPT-ASS-20B) peut être utilisé dans les téléphones mobiles est quelque chose de risqué, mais pas fou: avec une configuration adéquate de la couche d'exécution (Olllama, LM Studio ou l'application mobile correspondante), il semble parfaitement possible que nous pouvons avoir un Chatpt local sur notre mobile.
Celui qui permet à toutes nos données de ne pas partir (confidentialité par drapeau) et qui nous permet également d'économiser sur les coûts. L'avenir de l'IA local s'ouvre plus que jamais, et nous espérons seulement que cela deviendra une tendance pour d'autres entreprises qui développent des modèles ouverts. Celui-ci d'Openai est sans aucun doute une étape formidable et prometteuse pour ce futur théorique dans lequel nous avons des modèles de l'exécution massivement sur nos PC, dans nos mobiles … ou dans nos lunettes.
Dans Simseo | L'objectif a une excellente raison de lancer une gigantesque variante de flamme 4: Capacité de spécialisation