
Le nouveau cadre réduit l'utilisation de la mémoire et stimule l'efficacité énergétique pour l'analyse des graphiques AI à grande échelle
Bingocgn, un accélérateur de réseau neuronal de graphique évolutif et efficace qui permet l'inférence de graphiques à grande échelle en temps réel grâce à la partition de graphiques, a été développé par des chercheurs de l'Institut de science Tokyo, au Japon. Ce cadre révolutionnaire utilise une technique de quantification innovante de messages inter-partitions et un nouvel algorithme de formation pour réduire considérablement les demandes de mémoire et augmenter l'efficacité de calcul et énergétique.
Les réseaux de neurones graphiques (GNNS) sont de puissants modèles d'intelligence artificielle (AI) conçus pour analyser des données de graphes complexes et non structurés. Dans de telles données, les entités sont représentées comme des nœuds et les relations entre elles sont les bords. Les GNN ont été utilisés avec succès dans de nombreuses applications du monde réel, notamment les réseaux sociaux, la découverte de médicaments, la conduite autonome et les systèmes de recommandation. Malgré leur potentiel, la réalisation de l'inférence GNN en temps réel et à grande échelle, critique pour des tâches comme la conduite autonome, reste difficile.
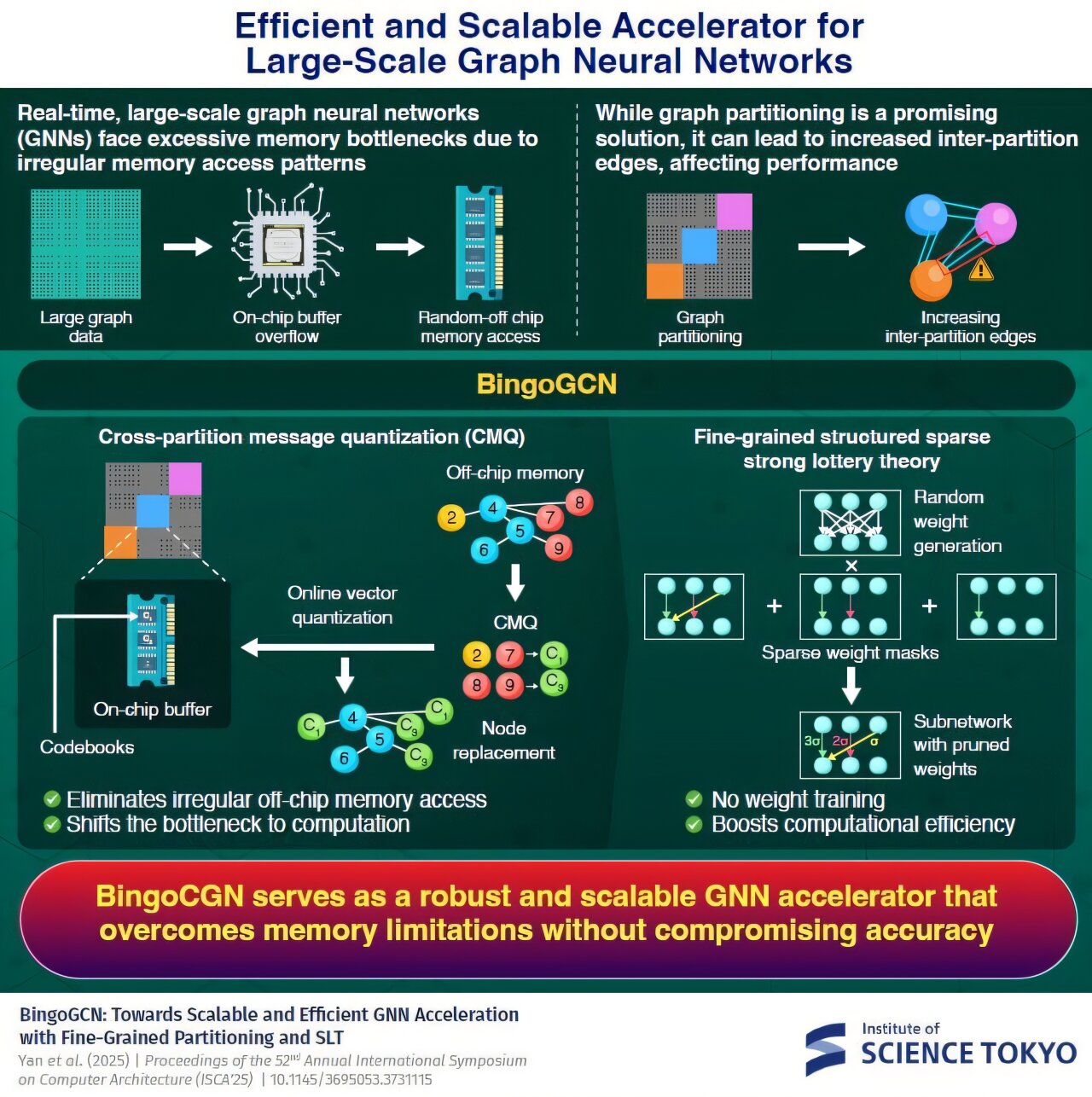
Les gros graphiques nécessitent une mémoire étendue, débordant souvent de tampons sur puce, qui sont des régions de mémoire intégrées dans une puce. Cela oblige le système à s'appuyer sur la mémoire plus lente. Étant donné que les données du graphique sont stockées de manière irrégulière, cela conduit à des modèles d'accès à la mémoire irrégulière, à une efficacité de calcul dégradante et à une augmentation de la consommation d'énergie.
Une solution prometteuse est le partitionnement du graphique, où les gros graphiques sont divisés en graphiques plus petits, chacun attribué son propre tampon sur puce. Il en résulte des modèles d'accès à la mémoire plus localisés et des exigences de taille tampon plus petites à mesure que le nombre de partitions augmente.
Cependant, cela n'est que partiellement efficace. Au fur et à mesure que le nombre de partitions augmente, les liens entre les partitions et les bords inter-partitions augmentent considérablement. Cela nécessite une augmentation de l'accès à la mémoire hors puce, limitant l'évolutivité.
Pour résoudre ce problème, une équipe de recherche dirigée par le professeur agrégé Daichi Fujiki de l'Institut des sciences Tokyo, au Japon, a développé un nouveau accélérateur GNN évolutif et efficace appelé Bingocgn. « Bingocgn utilise une nouvelle technique appelée quantification des messages inter-partitions (CMQ) qui résume le flux de messages interparties, éliminant l'accès à la mémoire irrégulière hors puce et un nouvel algorithme de formation qui stimule considérablement l'efficacité informatique », explique le Fujiki. Leurs résultats seront présentés lors des actes du 52e Symposium international annuel sur l'architecture informatique (ISCA '25) du 21 au 25 juin 2025.
CMQ utilise une technique appelée quantification vectorielle, qui regroupe les nœuds inter-partitions et les représente en utilisant des points appelés centroïdes. Les nœuds sont regroupés en fonction de leur distance, chaque nœud attribué à son centroïde le plus proche. Pour une partition donnée, ces centroïdes remplacent les nœuds interpartités, compressant efficacement les données de nœuds. Les centroïdes sont stockés dans des tableaux appelés livres de codes, qui résident directement dans le tampon sur puce.
CMQ permet donc une communication inter-partitionne sans avoir besoin d'un accès à la mémoire hors puce irrégulière et coûteux. De plus, comme cette méthode nécessite une lecture et une écriture fréquentes de nœuds et de centroïdes à la mémoire, cette méthode utilise une structure hiérarchique de type arborescence pour les livres de codes, avec des centroïdes parents et enfants, réduisant les demandes de calcul tout en maintenant la précision.
Alors que CMQ résout le goulot d'étranglement de la mémoire, il déplace le fardeau vers le calcul. Pour contrer cela, les chercheurs ont développé un nouvel algorithme de formation basé sur une forte théorie des billets de loterie. Dans cette méthode, le GNN est initialisé avec des poids aléatoires, générés sur puce à l'aide de générateurs de nombres aléatoires.
Ensuite, les poids inutiles sont taillés à l'aide d'un masque, formant un sous-réseau plus petit, moins dense ou clairsemé qui a une précision comparable à la GNN complète mais est significativement plus efficace à calculer. De plus, cette méthode intègre l'élagage structuré à grains fins (FG), qui utilise plusieurs masques avec différents niveaux de rareté, pour construire un sous-réseau encore plus petit et plus efficace.
« Grâce à ces techniques, BingocGGn obtient une inférence GNN haute performance même sur les données de graphes finement partitionnées, qui était auparavant considérée comme difficile », remarque Fujiki. « Notre implémentation matérielle, testée sur sept ensembles de données du monde réel, atteint une augmentation jusqu'à 65 fois et une augmentation de 107 fois de l'efficacité énergétique par rapport à l'accélérateur de pointe. »
Cette percée ouvre la porte au traitement en temps réel des données de graphiques à grande échelle, ouvrant la voie à diverses applications réelles des GNN.