
Le modèle de langue visuelle crée des plans pour une inspection automatisée des environnements
Les progrès récents dans le domaine de la robotique ont permis l'automatisation de diverses tâches du monde réel, allant de la fabrication ou de l'emballage de marchandises dans de nombreux contextes de l'industrie à l'exécution précise des procédures chirurgicales peu invasives. Les robots pourraient également être utiles pour inspecter les infrastructures et les environnements qui sont dangereux ou difficiles à accéder aux humains, comme les tunnels, les barrages, les pipelines, les chemins de fer et les centrales électriques.
Malgré leur promesse pour l'évaluation sûre des environnements réels, actuellement, la plupart des inspections sont toujours effectuées par des agents humains. Ces dernières années, certains informaticiens ont essayé de développer des modèles de calcul qui peuvent planifier efficacement les trajectoires que les robots devraient suivre lors de l'inspection des environnements spécifiques et s'assurer qu'ils exécutent des actions qui leur permettront de terminer les missions souhaitées.
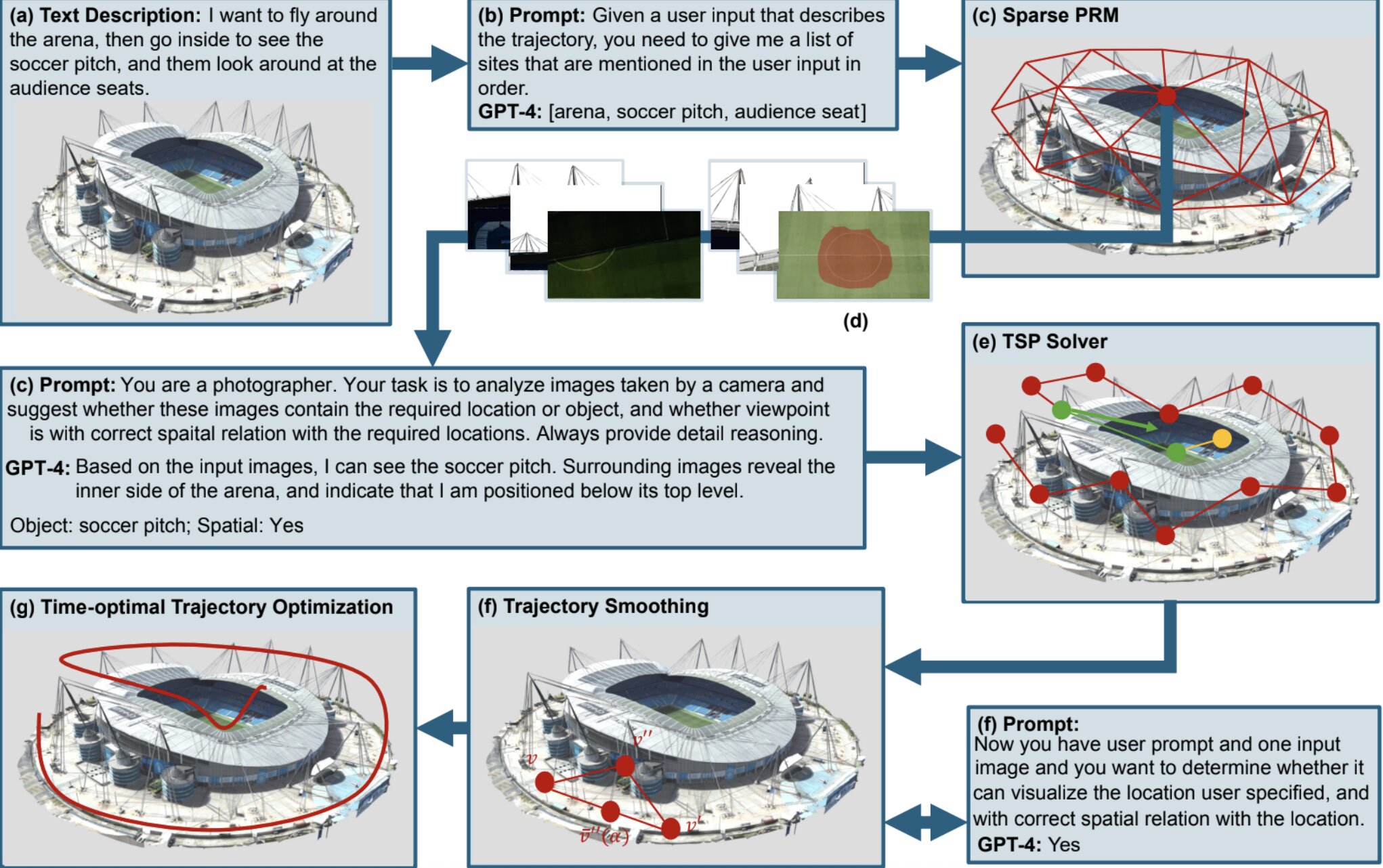
Des chercheurs de Purdue University et Lightspeed Studios ont récemment introduit une nouvelle technique de calcul sans formation pour générer des plans d'inspection basés sur des descriptions écrites, qui pourraient guider les mouvements des robots lorsqu'ils inspectent des environnements spécifiques. Leur approche proposée, décrite dans un article publié sur le arxiv Preprint Server, s'appuie spécifiquement sur des modèles de vision en langage de vision (VLMS), qui peuvent traiter à la fois des images et des textes écrits.
« Notre article a été inspiré par des défis du monde réel dans l'inspection automatisée, où la génération de voies d'inspection spécifiques aux tâches est essentiellement critique pour des applications telles que la surveillance des infrastructures », a déclaré à Tech Xplore de XingPeng Sun, premier auteur du journal.
« Alors que la plupart des approches existantes utilisent des modèles de vision (VLM) pour explorer des environnements inconnus, nous prenons une nouvelle direction en tirant parti des VLM pour naviguer dans des scènes 3D connues pour des tâches de planification d'inspection des robots à grain fin en utilisant des instructions en langage naturel. »
L'objectif clé de cette étude récente de Sun et de ses collègues était de développer un modèle de calcul qui permettrait à la génération rationalisée de plans d'inspection adaptés à des besoins ou des missions spécifiques. En outre, ils voulaient que ce modèle fonctionne bien sans nécessiter d'autres VLM à affinage affineux sur de grandes quantités de données, comme le font la plupart des autres modèles génératifs basés sur l'apprentissage automatique.
. Doi: 10.48550 / arxiv.2506.02917")
« Nous proposons un pipeline sans formation qui utilise un VLM pré-formé (par exemple, GPT-4O) pour interpréter les cibles d'inspection décrites dans le langage naturel ainsi que les images pertinentes », a expliqué Sun.
« Le modèle évalue les points de vue des candidats basés sur l'alignement sémantique, et nous tirons davantage davantage le GPT-4O pour raisonner sur les relations spatiales relatives (par exemple, à l'intérieur / à l'extérieur de la cible) à l'aide d'images multi-visualités. Une trajectoire d'inspection 3D optimisée est ensuite générée en résolvant un problème de vendeur itinérant (TSP) en utilisant des programmes de mixage pour les comptes pour la pertinence sémantique, la commande spatiale, et les contraintes de localisation. »
Le TSP est un problème d'optimisation classique qui vise à identifier l'itinéraire le plus court possible connectant plusieurs emplacements sur une carte, tout en considérant les contraintes et les caractéristiques d'un environnement. Après avoir résolu ce problème, leur modèle affine des trajectoires lisses pour le robot effectuant une inspection et des points de vue optimaux de la caméra pour capturer des sites d'intérêt.
« Notre nouvelle approche basée sur VLM sans formation pour la planification d'inspection des robots traduit efficacement les requêtes en langage naturel en trajectoires de planification d'inspection 3D fluide et précise pour les robots », a déclaré Sun et son conseiller, le Dr Aniket Bera. « Nos résultats révèlent également que les VLM de pointe, tels que GPT-4O, présentent de fortes capacités de raisonnement spatial lors de l'interprétation d'images multi-vues. »
Sun et ses collègues ont évalué leur modèle de génération de plan d'inspection proposé dans une série de tests, où ils lui ont demandé de créer des plans pour inspecter divers environnements réels, l'alimentation des images de ces environnements. Leurs résultats étaient très prometteurs, car le modèle a réussi à décrire des trajectoires lisses et des points de vue de caméra optimaux pour terminer les inspections souhaitées, prédisant les relations spatiales avec une précision de plus de 90%.
Dans le cadre de leurs futures études, les chercheurs prévoient de développer et de tester leur approche pour améliorer ses performances dans un large éventail d'environnements et de scénarios. Le modèle pourrait ensuite être évalué à l'aide de réels systèmes robotiques et finalement déployé dans des paramètres du monde réel.
« Nos prochaines étapes incluent l'extension de la méthode à des scènes 3D plus complexes, l'intégration de la rétroaction visuelle active pour affiner les plans à la volée et combinant le pipeline avec le contrôle du robot pour permettre le déploiement d'inspection physique en boucle fermée », a ajouté Sun et Bera.
Écrit pour vous par notre auteur Ingrid Fadelli, édité par Gaby Clark, et vérifié et examiné par Robert Egan – cet article est le résultat d'un travail humain minutieux. Nous comptons sur des lecteurs comme vous pour garder le journalisme scientifique indépendant en vie. Si ce rapport vous importe, veuillez considérer un don (surtout mensuel). Vous obtiendrez un sans publicité compte comme un remerciement.