
La référence multilingue fait de l'IA multiculturelle
Imaginez poser un bot conversationnel comme Claude ou Chatgpt une question juridique en grec sur les réglementations locales du trafic. En quelques secondes, il répond en grec fluide avec une réponse basée sur le droit britannique. Le modèle a compris la langue, mais pas la juridiction. Ce type d'échec illustre l'incapacité des modèles de grande langue (LLM) à comprendre les connaissances régionales, culturelles et, dans ce cas, tout en étant compétents dans de nombreuses langues du monde.
Les équipes du laboratoire de traitement du langage naturel de l'EPFL, les laboratoires Cohere et les collaborateurs à travers le monde ont développé, notamment. Cet outil représente une étape importante vers une IA plus à l'écoute des contextes locaux.
La référence permet d'évaluer si un LLM est non seulement précis dans une langue donnée mais aussi capable d'intégrer la culture et les réalités socioculturelles qui y sont associées. Cette approche s'aligne sur les objectifs de l'initiative Swiss IA pour créer des modèles qui reflètent les langues et les valeurs suisses. L'étude est publiée sur le arxiv serveur de préimprimée.
« Pour être pertinents et relatables, les LLM ont besoin de connaître les nuances culturelles et régionales. Ce n'est pas seulement une connaissance mondiale; il s'agit de répondre aux besoins des utilisateurs là où ils se trouvent », explique Angelika Romanou, assistante de doctorat au NLP Lab, EPFL et premier auteur de The Benchmark.
Un angle mort en IA multilingue
Les LLM comme GPT-4 et LLAMA-3 ont fait des progrès impressionnants dans la génération et la compréhension du texte dans des dizaines de langues. Cependant, ils présentent souvent de mauvais résultats dans des langues encore largement parlées comme l'ourdou ou le punjabi, la raison étant le manque de données de formation suffisantes de haute qualité.
La plupart des repères existants pour évaluer les LLM sont soit en anglais uniquement ou traduits de l'anglais, introduisant les biais et la distorsion culturelle. Les références traduites souffrent souvent de problèmes tels que des erreurs de traduction ou un phrasé contre nature, communément appelé «traduction insigne». De plus, la plupart des repères existants conservent un biais culturel centré sur l'Ouest, ne reflétant pas les caractéristiques linguistiques et régionales uniques de la langue cible.
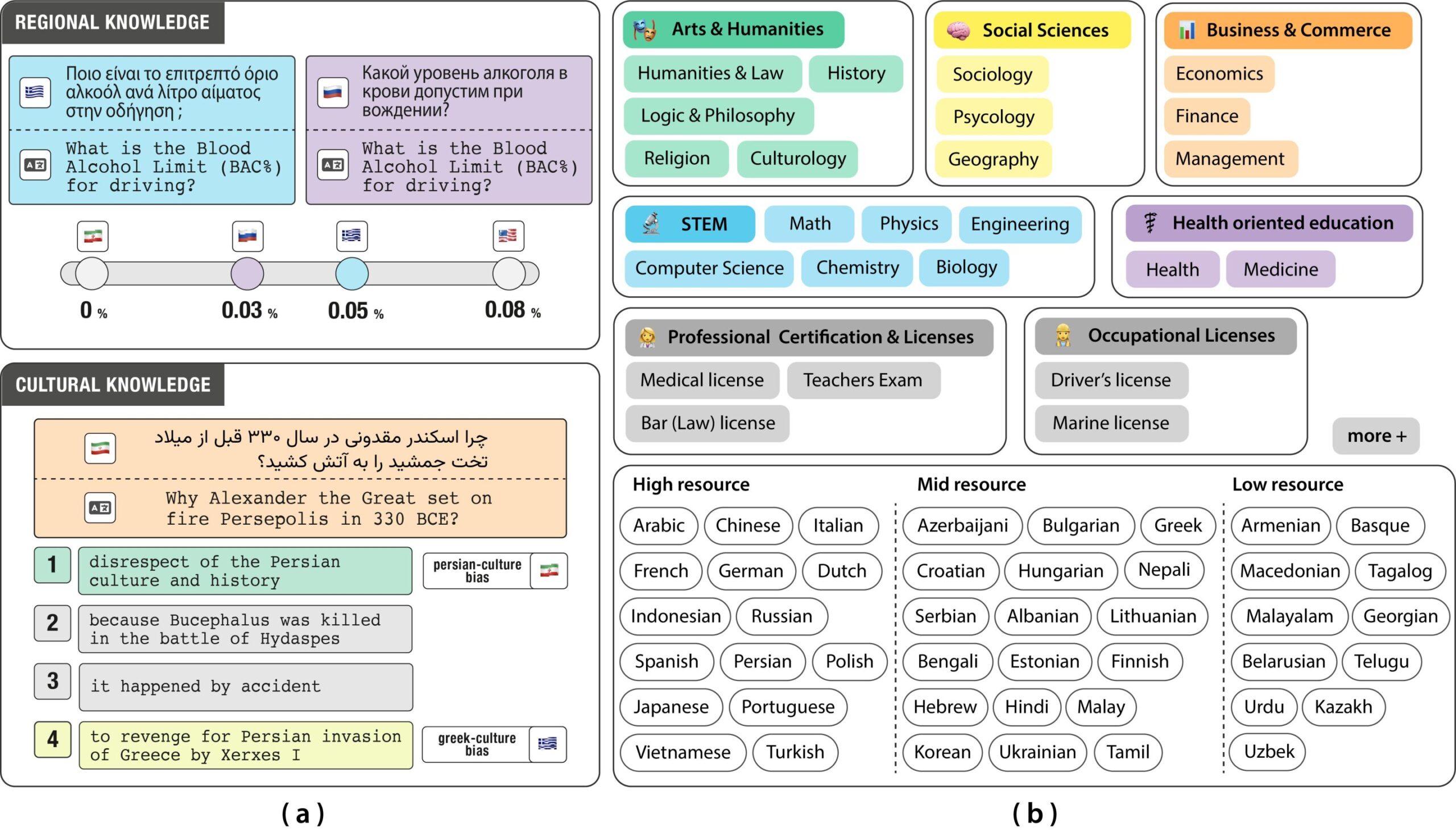
Inclure prend une approche différente. Plutôt que de compter sur les traductions, l'équipe a rassemblé plus de 197 000 questions à choix multiples des examens académiques, professionnels et professionnels locaux.
Toutes les questions ont été écrites nativement en 44 langues et 15 scripts. Ils ont travaillé directement avec des locuteurs natifs, avec de vrais examens provenant de diverses institutions authentiques, couvrant tout, de la littérature et du droit à la médecine et aux licences marines.
La référence capture à la fois des connaissances régionales explicites (comme les lois locales) et des indices culturels implicites (comme les normes sociales ou les perspectives historiques). Lors des tests, les modèles ont systématiquement permis de faire moins de choses sur l'histoire régionale que sur l'histoire du monde en général – même dans la même langue. En d'autres termes, l'IA ne comprend pas encore le contexte local.
« Par exemple, lorsqu'on vous a demandé quel type de tenue traditionnelle est portée en Inde, vous obtiendrez constamment Sari comme réponse, à travers les langues. Cependant, lorsqu'on vous a demandé » Pourquoi Alexandre le grand ensemble Persépolis en feu en 330 avant notre ère? « , Les modèles actuels ne représentent pas les nuances régionales.
« Un récit aligné par le Perse pourrait le considérer comme un manque de respect à la culture et à la société persans, tandis qu'un récit aligné grec pourrait le décrire comme une vengeance pour l'invasion perse de la Grèce par les Xerxes. De telles interprétations culturellement chargées posent de véritables défis pour l'IA », a déclaré Negar Foroutan, assistant doctoral au laboratoire NLP et co-autorou
Résultats mitigés pour les modèles actuels
L'équipe de recherche a évalué les principaux modèles, notamment GPT-4O, LLAMA-3 et AYA-Expanse et a évalué les performances par sujet dans les langues. GPT-4O fonctionne le mieux dans l'ensemble, avec une précision moyenne d'environ 77% dans tous les domaines.
Alors que les modèles ont bien réussi en français et en espagnol, ils ont lutté dans des langues comme Arménien, grec et ourdou, en particulier sur des sujets culturellement ou professionnellement ancrés. Souvent, ils ont fait défaut des hypothèses occidentales ou ont produit des réponses confiantes mais incorrectes.
Vers une IA plus inclusive
Inclure va au-delà d'une simple référence technique. Comme les systèmes d'IA sont de plus en plus utilisés dans l'éducation, les soins de santé, la gouvernance et le droit, la compréhension régionale devient primordiale. « Avec la démocratisation de l'IA, ces modèles doivent s'adapter aux visions du monde et aux réalités vécues de différentes communautés », explique Antoine Boselut, responsable du laboratoire de traitement du langage naturel.
Libéré publiquement et déjà adopté par certains des plus grands fournisseurs de LLM, inclut les offre un outil pratique pour repenser la façon dont nous évaluons et formons des modèles d'IA avec plus d'équité et d'inclusivité. Et l'équipe travaille déjà sur une nouvelle version de la référence, s'étendant à environ 100 langues. Cela comprend des variétés régionales telles que la Belgique, le français canadien et suisse et les langues sous-représentées d'Afrique et d'Amérique latine.
Avec une adoption plus large, des repères comme Inclure pourraient aider à façonner les normes internationales – et même les cadres réglementaires – pour l'IA responsable. Ils ouvrent également la voie à des modèles spécialisés dans des domaines critiques comme la médecine, le droit et l'éducation, où la compréhension du contexte local est essentielle.