
L'outil sépare automatiquement les données de formation et de test pour améliorer l'évaluation de l'IA
Un nouvel outil a été développé pour mieux évaluer les performances des modèles d'IA. Il a été développé par des bioinformaticiens de Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) et de l'Institut Helmholtz pour la recherche pharmaceutique SAARLAND (HIPS).
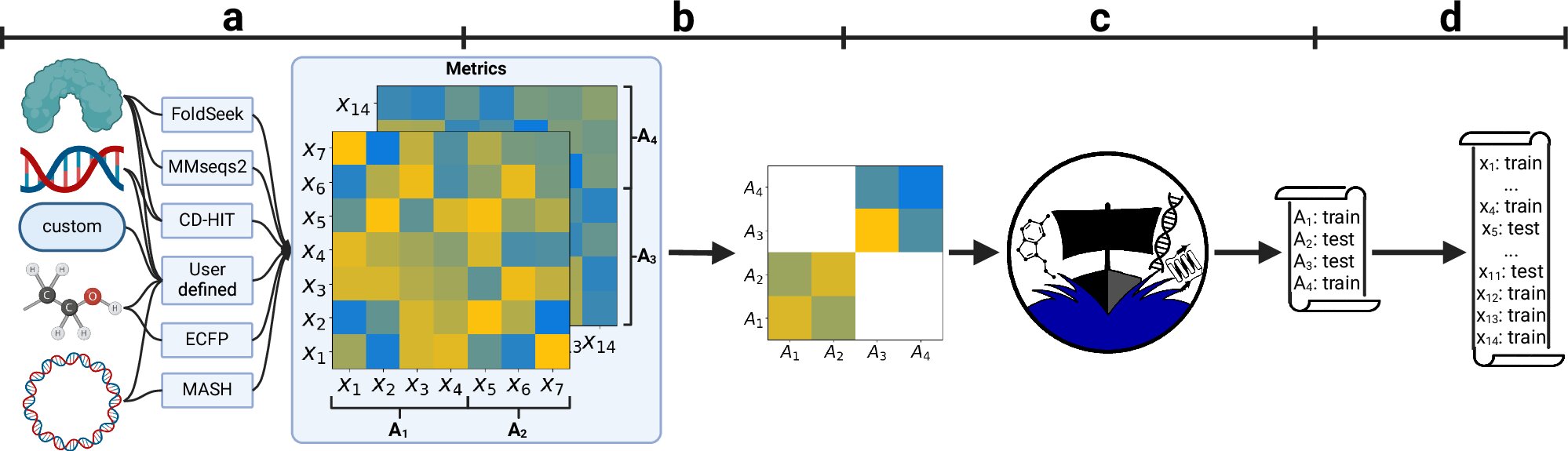
« DataSail » trie automatiquement les données de formation et de test afin qu'elles diffèrent autant que possible les unes des autres, permettant d'évaluer si les modèles d'IA fonctionnent de manière fiable avec différentes données. Les chercheurs ont maintenant présenté leur approche dans la revue Communications de la nature.
Les modèles d'apprentissage automatique sont formés avec d'énormes quantités de données et doivent être testés avant une utilisation pratique. Pour cela, les données doivent d'abord être divisées en un ensemble de formation plus large et un ensemble de tests plus petit – le premier est utilisé pour que le modèle apprenne, et le second est utilisé pour vérifier sa fiabilité.
« Ce n'est que si les données sont divisées de telle manière que les données de test diffèrent considérablement des données de formation peuvent être déterminées si le modèle peut ensuite gérer de nouvelles données, ce que l'on appelle les données hors distribution, dans la pratique », explique le professeur. Dr. David Blumenthal, bioinformaticien au Département d'intelligence artificielle en génie biomédical (AIBE) à Fau.
Les modèles d'IA sont souvent surestimés
Les algorithmes conventionnels ne sont généralement pas capables de cette division optimisée de données, c'est pourquoi les performances des modèles d'IA sont souvent surestimées. Avec des chercheurs des hanches, David Blumenthal a donc développé un outil qui empêche de tels mauvais juges et établit de nouvelles normes dans un domaine important de l'apprentissage automatique. L'outil, appelé DataSail, divise automatiquement les ensembles de données afin que les données de formation et de test soient aussi différentes que possible.
« DataSail est un outil gratuit et peut être utilisé pour tous les types de données, pas seulement dans la recherche biologique », explique Blumenthal. « Les utilisateurs doivent uniquement définir quelques paramètres pour leurs ensembles de données, et la taille de données fait le reste automatiquement et de manière cohérente. »
. Doi: 10.1038 / s41467-025-58606-8")
L'outil traite également les données d'interaction
DataSail est également le premier outil qui peut être utilisé pour le fractionnement automatisé des données d'interaction. Ces données multidimensionnelles jouent un rôle, par exemple, dans la recherche sur les médicaments.
« Imaginez que vous voulez développer des modèles d'IA qui prédisent l'interaction entre les médicaments et les protéines cibles », explique Blumenthal. « Ensuite, lorsque vous testez ces modèles, vous devez évaluer la façon dont ils fonctionnent pour des molécules de médicament modifiées d'une part et pour différentes protéines de l'autre. »
De plus, l'outil est capable de considérer les caractéristiques de classe, comme une distribution uniforme de sujets masculins et féminins dans les données de formation et de test. Cela empêche les tests d'un modèle de donner des résultats plus irréalistes pour un sexe que pour l'autre.
Le plan est de développer davantage l'outil dans les années à venir pour réduire le temps d'exécution des algorithmes et préparer encore plus les données pour divers scénarios pratiques.