

NVLM, la réponse open source de Nvidia à Multimodale Ai
NVLM 1.0 est une famille de Modèles linguistiques multiméaux de nvidia, Conçu pour devenir des semences à la fois chez les amateurs de vision et dans des activités purement textuelles. Cette version représente un pas en avant en époque dans le contexte deIntelligence artificielle open source (AI Technologies où le code source est disponible gratuitement pour quiconque pour une utilisation, une modification et une distribution), offrant des services compétitifs par rapport aux propriétaires d'autres sociétés de premier plan du secteur.

De plus, le PDG de Nvidia a lancé un message fort il y a quelque temps: « Nous avons créé une intelligence artificielle qui inclut le monde réel » qui trace une ligne droite et décidé de chaque développement individuel de l'IA.
Les modèles linguistiques conçus par Nvidia « apprennent les notions que les modèles actuels ne comprennent pas ». C'est l'essence du véritable défi que Nvidia apporte au marché mondial.

Qu'est-ce que NVLM 1.0 de nvidia
NVLM, acronyme de Modèle de langue de vision nvidia, est une suite de Modèles linguistiques multi-finis (MLLM) développé entièrement en interne par Nvidia. Ces modèles sont conçus pour gérer et traiter simultanément les données textuelles et visuelles, permettant une compréhension et une génération avancées de contenu multimodal.
La version 1.0 de NVLM représente la première itération de cette famille, visant à fournir des performances de niveau élevé dans des tâches qui nécessitent une profonde compréhension du texte et des images
Comme NVLM 1.0 est formé: une approche, une qualité et un raisonnement en deux phases
La formation NVLM 1.0 n'est pas simplement basée sur l'accumulation d'énormes quantités de données, mais sur une stratégie ciblée, divisée en deux phases distinctes mais synergiques, avec un objectif clair: rendre le modèle capable de comprendre et de pensernon seulement pour générer du texte ou décrire des images.
Pré-formation (pré-formation): « mieux la qualité que la quantité«
À ce stade, la NVLM est exposée à des ensembles de données multimodaux soigneusement sélectionnés, c'est-à-dire contenant du texte et des images combinées, conçue non pas par la taille, mais pour la diversité sémantique et la profondeur des tâches. Au lieu d'utiliser de grands volumes de données génériques (comme des images aléatoires à partir d'Internet), Nvidia a opté pour des sources qui:
- Présenter des relations complexes entre le texte Et image (par exemple, les tableaux décrits dans les mots, les graphistes commentés, les diagrammes techniques);
- Ils couvrent différentes zones: De la médecine aux mathématiques, de la géographie au design industriel;
- Ils sont proprescohérent et structuré, réduisant le bruit et améliorant l'apprentissage.
Le dernier point est l'essence réelle de la structure du modèle, car il brise de loin le pourcentage d'hallucinations pendant le traitement.
L'objectif est de créer un modèle qui sait comment établir des liens profonds entre le langage et la vision, en développant les fondations d'un raisonnement complexe.
Taune de fin supervisée (fin de tons fins sur le SFT): « Le moment où le modèle apprend à penser »
Cette deuxième phase sert à terminer et se spécialiser Les compétences déjà acquises. Ici, NVLM est formé avec:
- Ensembles de données textuels de haute qualité: pour améliorer ses compétences linguistiques, sa compréhension sémantique, sa cohérence logique et sa génération de texte fluide;
- L'ensemble de données Mulimigodi axé sur les tâches complexesen particulier:
- Mathématiques visuelles (par exemple, les problèmes avec les images, la géométrie, les équations insérées par des diagrammes);
- Raisonnement jumimal (par exemple, expliquer un graphique basé sur une légende ou analyser une scène pour répondre à une question).
En pratique, le modèle Non seulement il apprend à voir et à liremais un Déduire, expliquer, comparer et raisonner.
Nous nous rapprochons d'une IA qui a les mêmes comportements de réflexion qu'un humain.
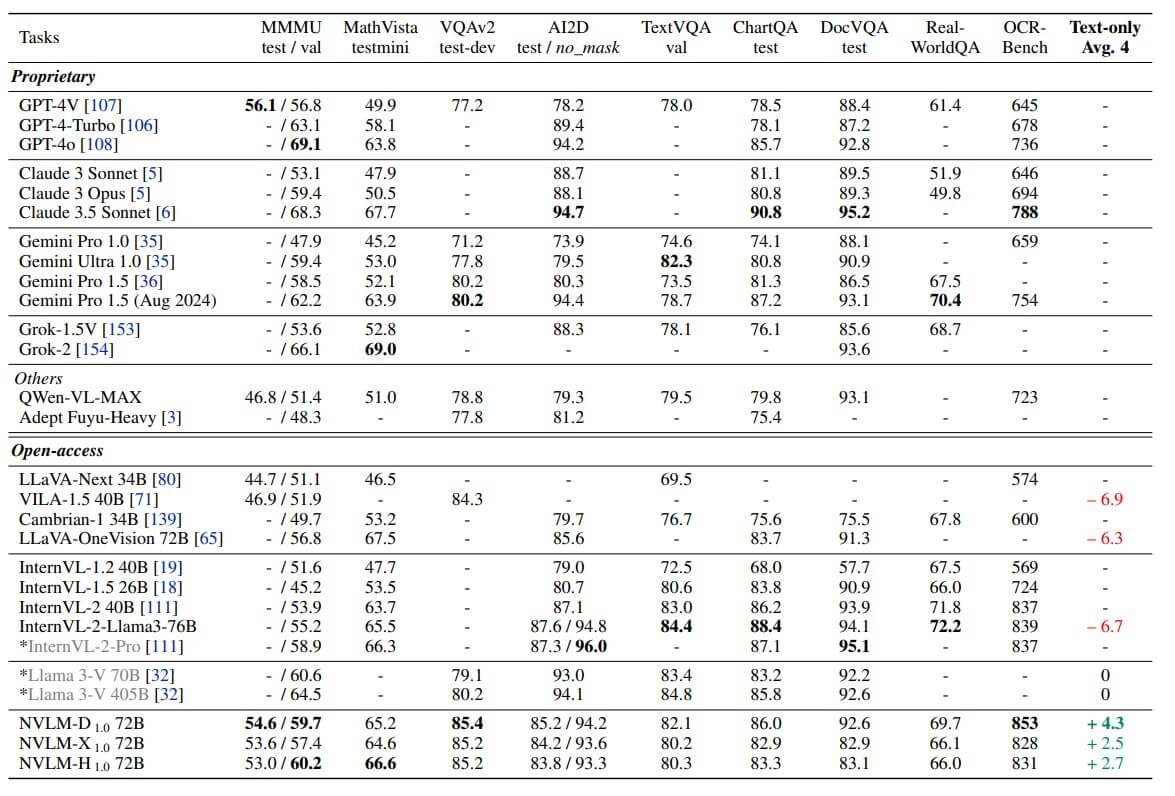
NVLM 1.0: Que peut faire, compétences et applications
NVLM 1.0 est conçu pour faire face à une large gamme de tâches multimodales et textuelles, notamment:
- OCR (reconnaissance des caractères optiques): excelle dans la reconnaissance de texte dans les images, surmonter des modèles concurrents sur le benchmark sous le nom de Banc OCR.
- Raisonnement jumimal: Capacité avancée à interpréter et raisonner sur des données visuelles et textuelles combinées, telles que l'analyse des graphiques et des tables.
- Emplacement et compréhension visuels: Identification précise des objets et interprétation de scénarios visuels complexes.
- Raisonnement logique et connaissance du monde: efficace pour appliquer les connaissances générales et le raisonnement logique sur le texte et les informations visuelles.
NVLM 1.0quelques exemples d'utilisation
1 et 1 Exemple
Une entreprise reçoit quotidiennement des centaines de documents numérisés: factures, contrats, reçus fiscaux et relations techniques. Ces documents incluent souvent des textes dans de petites polices, tables, logos, timbres et signatures, ce qui rend difficile le paiement de l'extraction précise des informations avec des solutions OCR traditionnelles.
Solution avec NVLM 1.0
Grâce à la capacité multimodale avancée de NVLM 1.0 et de son système « Tile Tagging 1D » Pour les images haute résolution, c'est possible:
- Chargez le document en tant qu'image (par exemple un PDF numérisé).
- NVLM analyse l'image, reconnaît le texte même s'il est tourné, assombrit ou distribué sur plusieurs colonnes.
- La sortie est un texte structuréprêt à être:
- Publié dans un Gestion de l'ERP;
- utilisé pour le surveillance des coûts ou pour le Entrée de date automatique;
- Étiquettes sémantiques déposées numériquement (par exemple, « Fournisseur Facture Q3 2025 »).
Plus par rapport aux modèles précédents:
- Reconnaître mieux je caractères spéciaux (par exemple, symboles mathématiques, formules, devises).
- Intègre également un premier niveau de compréhension sémantique: Par exemple, il peut étiqueter automatiquement « montant à payer », « date d'expiration », « numéro de facture », etc.
2. Exemple
- Un directeur financier d'une petite entreprise veut une analyse automatique des KPI mensuels, générés dans PDF par un logiciel de gestion avec des graphiques et des tables.
Avec NVLM 1.0:
- CFO charge le document PDF.
- Pose une question comme:
« Pourquoi êtes-vous descendu en février? » - NVLM compare les graphiques de vente, les articles de dépenses et le texte explicatif dans le document.
- Il répond en langage naturel, soulignant la corrélation entre l'augmentation des dépenses de marketing et les revenus stables.
Avantages distinctifs par rapport aux modèles précédents
NVLM 1.0 répond à Explications raisonnéespas seulement des résumés.
Il ne se limite pas à la lecture des données: Les relie et les interprète.
Reconnaître Modèles visuels et sémantiques (par exemple, croissance lente, fluctuations, valeurs aberrantes).
Pour en savoir plus