
Le modèle AI classe les images avec un arbre hiérarchique de large à spécifique
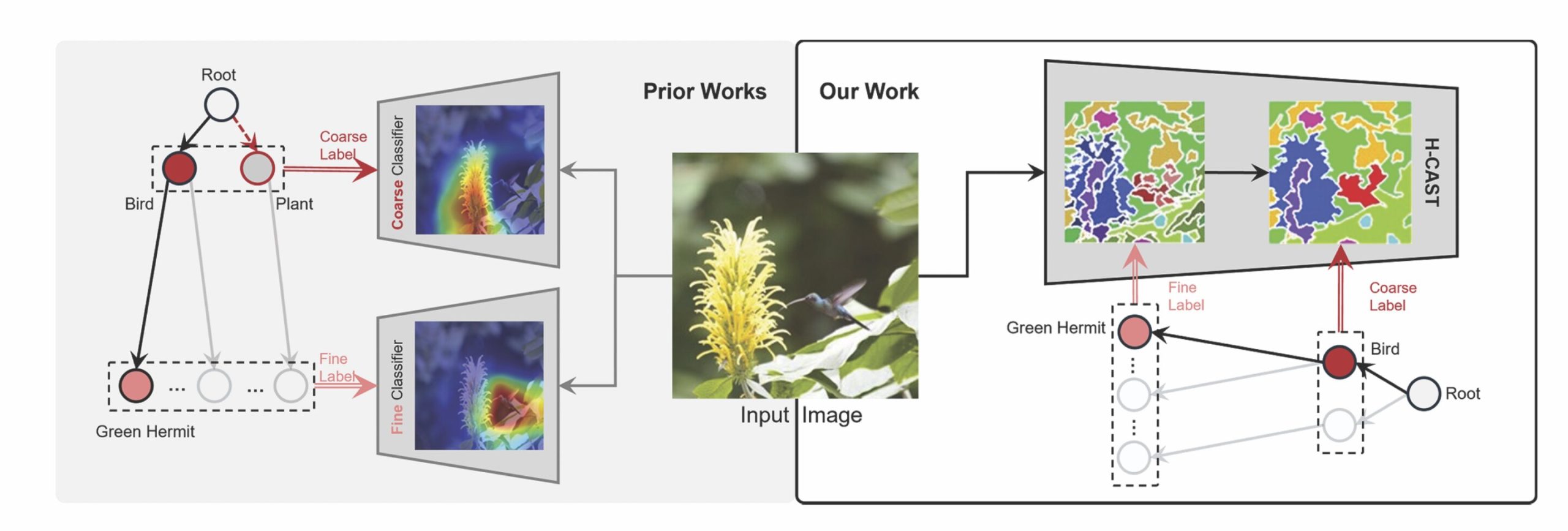
Un nouveau modèle d’IA, H-Cast, regroupe les détails fins dans les concepts au niveau de l’objet alors que l’attention passe des couches inférieures aux couches élevées, en sortant un arbre de classification – comme un oigle, un aigle, un pygargue à tête blanche – plutôt que de se concentrer uniquement sur la reconnaissance fine.
La recherche a été présentée lors de la Conférence internationale sur les représentations d’apprentissage à Singapour et s’appuie sur le modèle antérieur de l’équipe, Cast – l’homologue de la classification à un niveau à la terre visuelle. Le document est également publié sur le arxiv serveur de préimprimée.
Alors que certains soutiennent que l’apprentissage en profondeur peut fournir de manière fiable une classification à grains fins et inférer des catégories plus larges, cette tactique ne fonctionne qu’avec des images claires.
« Les applications du monde réel impliquent de nombreuses images imparfaites. Si un modèle se concentre uniquement sur la classification à grains fins, il abandonne avant même qu’il ne commence sur des images qui n’ont pas suffisamment d’informations pour soutenir ce niveau de détail, » a déclaré Stella Yu, professeur d’informatique et d’ingénierie à UM et auteur de l’étude.
La classification hiérarchique surmonte ce problème, fournissant une classification à plusieurs niveaux de détail pour la même image. Cependant, jusqu’à présent, les modèles hiérarchiques ont lutté contre les incohérences qui accompagnent le traitement de chaque niveau comme sa propre tâche de classification.
Par exemple, lors de l’identification d’un oiseau, la classification à grain fin dépend souvent de détails locaux comme la forme du bec ou la couleur de la plume, tandis que les étiquettes grossières nécessitent des fonctionnalités globales comme la forme globale. Lorsque ces deux niveaux sont déconnectés, cela peut entraîner un classificateur fin « perruche verte » tandis que le classificateur grossier prédit « usine. »
Le nouveau modèle concentre à la place tous les niveaux sur le même objet à différents niveaux de détail en alignant les prédictions fines à l’autre grâce à la segmentation intra-image.
Des modèles hiérarchiques précédents formés de grossiers à spécifiques, en se concentrant sur la logique de l’étiquetage sémantique qui passe du général à spécifique (par exemple, oiseau, colibri, ermite verte). H-Cast s’entraîne plutôt dans l’espace visuel où la reconnaissance commence par de beaux détails comme les becs et les ailes composés de structures plus grossières, conduisant à un meilleur alignement et à une précision.
« La plupart des travaux antérieurs dans la classification hiérarchique se sont concentrés sur la seule sémantique, mais nous avons constaté que la mise à la terre visuelle cohérente à travers les niveaux peut faire une énorme différence. En encourageant les modèles à «voir» la hiérarchie d’une manière visuellement cohérente, nous espérons que ce travail inspire un changement vers des systèmes de reconnaissance plus intégrés et interprétables, » a déclaré Séulki Park, chercheur postdoctoral en informatique et ingénierie à l’Université du Michigan et auteur principal de l’étude.
Contrairement aux méthodes antérieures, l’équipe de recherche a mis à profit la segmentation non supervisée – utilisée généralement pour identifier les structures au sein d’une image plus grande – pour soutenir la classification hiérarchique. Ils démontrent que son mécanisme de regroupement visuel peut être appliqué efficacement à la classification sans nécessiter d’étiquettes au niveau du pixel et aide à améliorer la qualité de la segmentation.
Pour démontrer l’efficacité du nouveau modèle, H-Cast a été testé sur quatre ensembles de données de référence et comparé aux modèles hiérarchiques (FGN, HRN. Transhp, Hier-Vit) et les modèles de base (VIT, Cast, Hie).
« Notre modèle a surperformé le clip à tirs zéro et les lignes de base de pointe sur les repères de classification hiérarchique, atteignant à la fois une précision plus élevée et des prédictions plus cohérentes, » dit yu.
Par exemple, dans l’ensemble de données des races, la précision complète de H-Cast était 6% plus élevée que la pointe précédente et 11% plus élevée que les lignes de base.
L’analyse du voisin le plus proche au niveau des fonctionnalités montre également que H-Cast récupère des échantillons sémantiquement et visuellement cohérents à travers les niveaux de hiérarchie – contrairement aux modèles antérieurs qui récupèrent souvent des échantillons visuellement similaires mais sémantiquement incorrects.
Ce travail pourrait potentiellement être appliqué à toute situation qui nécessite une compréhension des images à plusieurs niveaux. Cela pourrait particulièrement profiter à la surveillance de la faune, en identifiant les espèces dans la mesure du possible, mais en retombant sur des prédictions plus grossières. Le cast H peut également aider les véhicules autonomes à interpréter une entrée visuelle imparfaite comme les piétons occlus ou les véhicules distants, aidant le système à prendre des décisions approximatives et approximatives à des niveaux de détail plus grossiers.
« Les humains se replient naturellement sur des concepts plus grossiers. Si je ne peux pas dire si une image est d’un Pembroke Corgi, je peux toujours dire avec confiance que c’est un chien. Mais les modèles échouent souvent à ce type de raisonnement flexible. Nous espérons éventuellement construire un système qui peut adapter son niveau de prédiction comme nous le faisons, » ledit parc.
H-Cast a été formé et testé à l’aide de l’informatique à haute performance ARC à UM.
UC Berkeley, MIT et les fondations à l’échelle ont également contribué à cette recherche.