

Deepseek fait de même que les modèles les plus avancés d’Openai avec beaucoup moins de ressources. La clé: « apprentissage du renforcement »
Le monde entier se demande comment il est possible que les modèles de Deepseek soient devenus les grands protagonistes d’aujourd’hui dans le domaine de l’intelligence artificielle du jour au lendemain. La réponse est relativement simple. Ces modèles ont réussi à démontrer que Vous pouvez faire plus avec beaucoup moins.
Deepseek V3 et Deepseek-R1 sont comparables respectivement à GPT-4 ou O1 OpenAI, mais on estime que leur formation a été beaucoup moins chère et que son inférence, bien sûr, est: les prix de l’API Deepseek sont parfois jusqu’à 35 plus bas que ceux d’Openai, mais cela fait se demander comment cela est possible.
La réponse est claire, et c’est parce que nous avons à notre disposition les rapports techniques de ces modèles d’IA. Précisément son étude nous a permis de clarifier Quelles sont les techniques que ce laboratoire de R&D chinois a utilisé pour développer ces modèles si efficaces et capables.
De nombreuses techniques, un seul objectif: l’efficacité
Il existe plusieurs différences qui rendent le nouveau modèle de Deepseek particulièrement efficace. Il est expliqué en détail ses créateurs dans le rapport technique détaillé accessible au public. Voici les plus pertinents:
- Profondeur (« Mélange d’experts »): dans des modèles tels que GPT-3.5, le modèle entier a été activé à la fois dans la formation et l’inférence (lorsque nous l’utilisons). Cependant, tous les composants du modèle ne sont pas nécessaires pour nos demandes. La technique MOE – déjà introduite avec Deepseek V2 – divise précisément le modèle en plusieurs « experts » et active uniquement ceux qui sont nécessaires en fonction de la demande. GPT-4 est déjà un modèle MOE. Mais comme nous l’avons dit, Depseekmoe est même allé plus loin et se différenciait des experts encore plus spécialisés, en plus d’utiliser des experts un peu plus généralistes qui pourraient apporter de la valeur à certaines demandes. La gestion de tous ces experts spécialisés ou généralistes ne profite pas seulement à l’inférence, mais aussi à la phase de formation, ce qui la rend plus efficace. Cette technique est similaire à celle du «test de mise à l’échelle du temps», qui ajuste également la taille ou la complexité d’un modèle pendant l’efficacité.
- Profondeur (Attention latente multi-tête): Il s’agit d’une autre amélioration substantielle – même plus que la précédente, et également introduite avec Deepseek V2-qui affecte la façon dont la mémoire est gérée dans ces modèles. Normalement, il est nécessaire de charger à la fois le modèle et la fenêtre de contexte entière – celle qui nous permet d’écrire des invites et d’inclure des textes longs, par exemple. Les fenêtres de contexte sont particulièrement coûteuses car chaque jeton nécessite à la fois une clé et leur valeur correspondante. Avec l’amélioration introduite avec cette technique, ce qui a été rendu possible était de comprimer cet entrepôt de clés et de valeurs, réduisant considérablement l’utilisation de la mémoire pendant l’inférence.
- Équilibrage de charge sans auxiliaire -los: Si nous imaginons un modèle comme un grand orchestre, chaque musicien est un « expert » dans le modèle. Pour jouer une pièce complexe, tous les musiciens ne sont pas nécessaires tout le temps. Traditionnellement, les « pertes auxiliaires », ont été utilisées pour s’assurer que tous les musiciens jouaient suffisamment, mais ces pertes pourraient interférer avec cette interprétation de la pièce musicale (formation modèle), qui pourrait dégrader les performances générales. Avec Deepseek v3, le modèle est capable d’équilibrer le travail de chaque expert dynamiquement. Cela fait la formation la plus simple, directe et efficace en éliminant les «pertes auxiliaires». De plus, l’élimination des interférences permet au modèle d’apprendre mieux et avec moins de ressources … et d’obtenir de meilleurs résultats.
- Objectif de formation de prédiction multi-token: Prédire souvent le mot suivant dépend de plusieurs mots ou contextes précédents. Avec cette technique au lieu de ne prévoir que le mot suivant, le modèle apprend à prédire plusieurs mots en même temps. Cela rend les textes plus naturels et compréhensibles et moins ambigus, mais accélère également la formation en réduisant le nombre d’étapes nécessaires pour générer la séquence de texte complète.
- FP8 Formation de précision mixte: L’utilisation de nombres FP8 permet de réduire considérablement la consommation de mémoire et accélère les calculs. Certaines parties critiques du modèle continuent d’utiliser la formation FP32 pour garantir la précision, mais il y a un autre avantage supplémentaire de FP8: la taille des modèles est réduite. D’autres modèles utilisent des techniques telles que la quantification ou l’élagage des paramètres. Bien que OpenAI ne donne pas de données sur GPT-4 dans cette section, l’hypothèse est qu’elle fonctionne avec BF16, plus coûteuse en termes de mémoire. Bien que FP8 conduit théoriquement à des modèles moins précis, d’autres techniques complémentaires telles que la quantification à grains fins sont utilisées pour réduire l’impact négatif des valeurs qui sortent du commun, ce qui rend possible une formation stable.
- Communication tout à nœud: Pendant la formation, il est nécessaire d’échanger constamment des informations entre tous les nœuds (ordinateurs) connectés dans les centres de données de formation. Cela peut devenir un goulot d’étranglement, mais ces nouvelles techniques Deepseek V3 comprennent des protocoles de communication efficaces, une réduction du trafic de données et une synchronisation efficace pour accélérer la formation et, encore une fois, réduire les coûts de ce processus.
Renforcement et «distillation» l’apprentissage comme des clés
Mais en plus de toutes ces techniques, les responsables de Deepseek V3 expliquent comment ils l’ont appuyé avec 14,8 milliards de jetons, un processus auquel un ajustement supervisé a suivi (réglage fin, SFT) et plusieurs étapes de Apprentissage par renforcement (apprentissage du renforcement, RL). La phase SFT qui est mentionnée dans le rapport Deepseek V3 a été complètement omise dans le cas de Deepseek-R1.
Cependant, l’apprentissage par renforcement est un protagoniste absolu dans le développement des deux modèles, en particulier dans R1. La technique est bien connue dans le domaine de l’intelligence artificielle, et c’est comme si nous formions un chien avec des prix et des punitions. Le modèle apprend à mieux répondre en donnant des récompenses si vous faites bien. Au fil du temps, le modèle apprend à prendre des mesures qui maximisent la récompense à long terme. Dans Deepseek, l’apprentissage du renforcement est utilisé pour décomposer des problèmes complexes en étapes plus petites.
Le rapport technique Deepseek R1 indique également comment ce modèle utilise directement les techniques RL sur le modèle de base, sans avoir besoin d’une formation supervisée. Cela économise des ressources informatiques.
L’appel entre également en jeu ici Chaîne de réflexion (chaîne de choses)également mentionné dans le rapport technique. Cela fait référence à la capacité d’un modèle de langue à montrer les étapes intermédiaires de son raisonnement. Le modèle fournit non seulement une réponse: il explique également comment il est arrivé à cette réponse.
Cela améliore non seulement la transparence (nous savons « ce qui pense »), mais permet d’identifier les erreurs et d’améliorer la précision. La combinaison des deux techniques rend le comportement en profondeur dans le stade d’inférence particulièrement remarquable.
Dans le cas de Deepseek R1, il existe d’autres techniques qui permettent également de la rendre particulièrement efficace. Parmi eux, la distillation des modèles se démarque. Quel est ce processus?
Le Distillation du modèle C’est comme enseigner à un plus petit « modèle d’étudiant » pour se comporter comme un « modèle de professeur » plus grand et plus ancien. Un petit modèle est formé pour imiter les capacités et le comportement d’un grand modèle, mais avec moins de ressources de calcul. L’objectif est clair: que le petit modèle est plus rapide et plus efficace, mais tout aussi intelligent dans des tâches spécifiques.
Les développeurs Deepseek-R1 mettent en évidence la façon dont ils ont utilisé de petits modèles tels que QWEN (de 1,5b à 32b) ou appeler le 3.3 (8b et 70b-instruments) en utilisant 800 000 échantillons divulgués avec Deepseek-R1. Dans ces modèles, seuls l’apprentissage supervisé et le non-apprentissage pour le renforcement ont été utilisés car ils voulaient démontrer l’efficacité de la technique de distillat. Les résultats de ce processus ont été observés dans les repères publiés dans ce rapport technique: même plus petit que ses concurrents, leur comportement était meilleur.
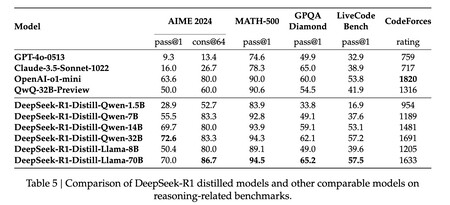
Plusieurs repères semblent clairement indiquer que les performances des variantes distillées de Deepseek R1 sont supérieures à celles de ses concurrents.
Il existe d’autres améliorations supplémentaires dans ce modèle, mais sans aucun doute, celles-ci sont les plus importantes lors de la réalisation de cette efficacité et de « faire plus avec moins ». La documentation de Deepseek est fantastique et est sûrement très utile pour que d’autres projets dans ce domaine continuent d’évoluer et de s’améliorer, mais aujourd’hui une chose est claire: le résultat de ces améliorations est spectaculaire, et les modèles de DePseek se comportent si bien ou mieux que ses concurrents, car nous ont pu vérifier dans notre vaste comparatif.
Dans Simseo | Les sanctions ont été essentielles: Deepseek a dû tirer l’ingéniosité pure, brisant le paradigme « plus = meilleur »