
Une nouvelle méthode prévoit le calcul et les coûts énergétiques pour les modèles d’IA durables
Le processus de mise à jour des modèles d’apprentissage profond/IA lorsqu’ils sont confrontés à de nouvelles tâches ou doivent s’adapter à des changements de données peut avoir des coûts importants en termes de ressources informatiques et de consommation d’énergie. Les chercheurs ont développé une nouvelle méthode qui prédit ces coûts, permettant aux utilisateurs de prendre des décisions éclairées sur le moment où mettre à jour les modèles d’IA pour améliorer la durabilité de l’IA. L’étude est publiée sur le arXiv serveur de préimpression.
« Des études ont été réalisées pour rendre plus efficace la formation des modèles d’apprentissage profond », explique Jung-Eun Kim, auteur correspondant d’un article sur ces travaux et professeur adjoint d’informatique à l’Université d’État de Caroline du Nord. « Cependant, au cours du cycle de vie d’un modèle, il devra probablement être mis à jour plusieurs fois. L’une des raisons est que, comme le montre notre travail ici, le recyclage d’un modèle existant est beaucoup plus rentable que la formation d’un nouveau modèle à partir de zéro.
« Si nous voulons résoudre les problèmes de durabilité liés à l’IA d’apprentissage profond, nous devons examiner les coûts informatiques et énergétiques tout au long du cycle de vie d’un modèle, y compris les coûts associés aux mises à jour. Si vous ne pouvez pas prédire à l’avance quels seront les coûts, il Il est impossible de s’engager dans le type de planification qui rend possible les efforts de développement durable. Cela rend notre travail ici particulièrement précieux.
La formation d’un modèle d’apprentissage en profondeur est un processus gourmand en calcul, et les utilisateurs souhaitent durer le plus longtemps possible sans avoir à mettre à jour l’IA. Cependant, deux types de changements peuvent survenir et rendre ces mises à jour inévitables. Premièrement, la tâche exécutée par l’IA devra peut-être être modifiée. Par exemple, si un modèle était initialement chargé de classer uniquement les chiffres et les symboles de circulation, vous devrez peut-être modifier la tâche pour identifier également les véhicules et les humains. C’est ce qu’on appelle un transfert de tâches.
Deuxièmement, les données que les utilisateurs fournissent au modèle peuvent changer. Par exemple, vous devrez peut-être utiliser un nouveau type de données, ou peut-être que les données avec lesquelles vous travaillez sont codées d’une manière différente. Quoi qu’il en soit, l’IA doit être mise à jour pour s’adapter au changement. C’est ce qu’on appelle un changement de distribution.
« Indépendamment de ce qui justifie la nécessité d’une mise à jour, il est extrêmement utile pour les praticiens de l’IA d’avoir une estimation réaliste de la demande de calcul qui sera requise pour la mise à jour », explique Kim. « Cela peut les aider à prendre des décisions éclairées sur le moment où effectuer la mise à jour, ainsi que sur la quantité de calcul dont ils auront besoin pour budgétiser la mise à jour. »
Pour prévoir quels seront les coûts de calcul et d’énergie, les chercheurs ont développé une nouvelle technique qu’ils appellent REpresentation Shift QUantifying Estimator (RESQUE).
Essentiellement, RESQUE permet aux utilisateurs de comparer l’ensemble de données sur lequel un modèle d’apprentissage en profondeur a été initialement formé au nouvel ensemble de données qui sera utilisé pour mettre à jour le modèle. Cette comparaison est effectuée de manière à estimer les coûts de calcul et d’énergie associés à la réalisation de la mise à jour.
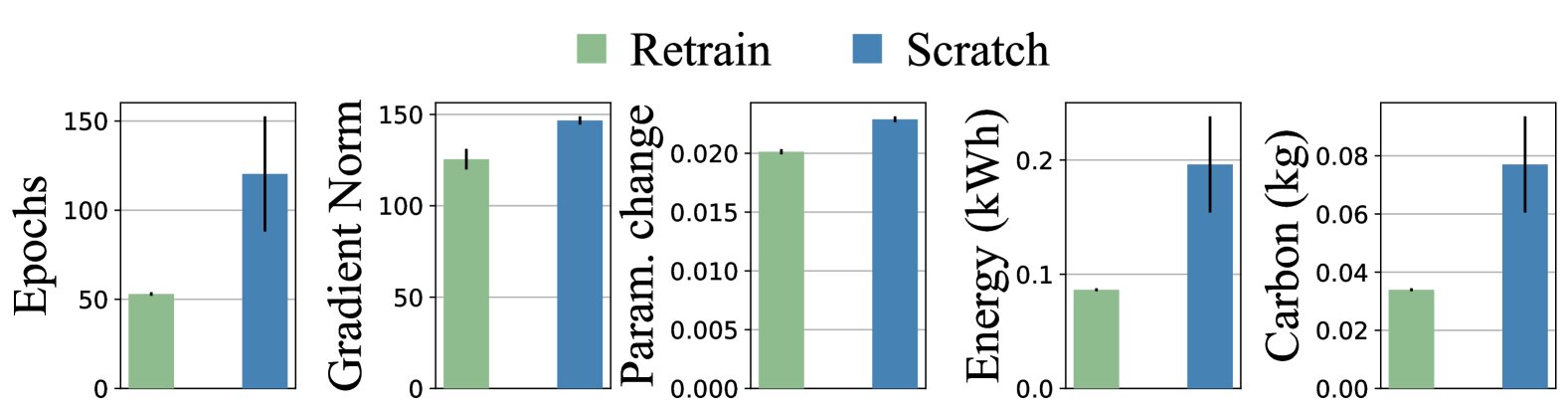
Ces coûts sont présentés sous la forme d’une valeur d’indice unique, qui peut ensuite être comparée à cinq métriques : les époques, le changement de paramètre, la norme de gradient, le carbone et l’énergie. Les époques, les changements de paramètres et la norme de gradient sont autant de moyens de mesurer la quantité d’effort de calcul nécessaire pour recycler le modèle.
« Cependant, pour donner une idée de ce que cela signifie dans un contexte plus large de développement durable, nous indiquons également aux utilisateurs la quantité d’énergie, en kilowattheures, qui sera nécessaire pour recycler le modèle », explique Kim. « Et nous prévoyons quelle quantité de carbone, en kilogrammes, sera libérée dans l’atmosphère afin de fournir cette énergie. »
Les chercheurs ont mené des expériences approfondies impliquant plusieurs ensembles de données, de nombreux changements de distribution différents et de nombreux changements de tâches différents pour valider les performances de RESQUE.
« Nous avons constaté que les prédictions de RESQUE correspondaient très étroitement aux coûts réels liés à la mise à jour du modèle d’apprentissage en profondeur », explique Kim. « De plus, comme je l’ai noté plus tôt, toutes nos découvertes expérimentales nous indiquent que la formation d’un nouveau modèle à partir de zéro nécessite beaucoup plus de puissance de calcul et d’énergie que le recyclage d’un modèle existant. »
À court terme, RESQUE est une méthodologie utile pour quiconque a besoin de mettre à jour un modèle d’apprentissage profond.
« RESQUE peut être utilisé pour aider les utilisateurs à budgétiser les ressources de calcul pour les mises à jour, leur permettre de prédire la durée de la mise à jour, etc. », explique Kim.
« Dans une perspective plus large, ces travaux offrent une compréhension plus approfondie des coûts associés aux modèles d’apprentissage profond tout au long de leur cycle de vie, ce qui peut nous aider à prendre des décisions éclairées concernant la durabilité des modèles et la manière dont ils sont utilisés. Parce que si nous voulons Pour que l’IA soit viable et utile, ces modèles doivent être non seulement dynamiques mais durables. »
L’article, « RESQUE : Quantifying Estimator to Task and Distribution Shift for Sustainable Model Reusability », sera présenté lors de la 39e conférence de l’Association pour l’avancement de l’intelligence artificielle (AAAI) sur l’intelligence artificielle, qui se tiendra du 25 février au mars. 4 à Philadelphie, Pennsylvanie. Le premier auteur de l’article est Vishwesh Sangarya, étudiant diplômé à NC State.