

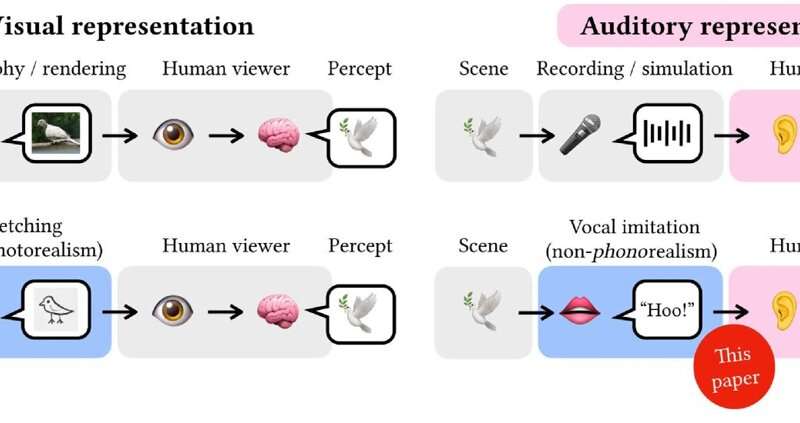
Un modèle d’IA inspiré par l’homme peut produire et comprendre des imitations vocales de sons quotidiens
Que vous décriviez le bruit du moteur de votre voiture défectueux ou que vous miauliez comme le chat de votre voisin, imiter les sons avec votre voix peut être un moyen utile de transmettre un concept lorsque les mots ne suffisent pas.
L’imitation vocale est l’équivalent sonore du griffonnage d’une image rapide pour communiquer quelque chose que vous avez vu, sauf qu’au lieu d’utiliser un crayon pour illustrer une image, vous utilisez votre conduit vocal pour exprimer un son. Cela peut sembler difficile, mais c’est quelque chose que nous faisons tous intuitivement : pour en faire l’expérience par vous-même, essayez d’utiliser votre voix pour reproduire le son d’une sirène d’ambulance, d’un corbeau ou d’une cloche qui sonne.
Inspirés par la science cognitive de la façon dont nous communiquons, des chercheurs du Laboratoire d’informatique et d’intelligence artificielle du MIT (CSAIL) ont développé un système d’IA capable de produire des imitations vocales de type humain sans formation et sans jamais avoir « entendu » une impression vocale humaine auparavant. . Les résultats sont publiés sur le arXiv serveur de préimpression.
Pour y parvenir, les chercheurs ont conçu leur système pour produire et interpréter des sons un peu comme nous le faisons. Ils ont commencé par construire un modèle du conduit vocal humain qui simule la façon dont les vibrations de la boîte vocale sont façonnées par la gorge, la langue et les lèvres. Ensuite, ils ont utilisé un algorithme d’IA d’inspiration cognitive pour contrôler ce modèle de conduit vocal et lui faire produire des imitations, en tenant compte des manières spécifiques au contexte que les humains choisissent de communiquer le son.
Le modèle peut effectivement prendre de nombreux sons du monde et en générer une imitation humaine, y compris des bruits comme le bruissement des feuilles, le sifflement d’un serpent et l’approche d’une sirène d’ambulance. Leur modèle peut également être exécuté à l’envers pour deviner les sons du monde réel à partir d’imitations vocales humaines, de la même manière que certains systèmes de vision par ordinateur peuvent récupérer des images de haute qualité basées sur des croquis. Par exemple, le modèle peut distinguer correctement le son d’un humain imitant le « miaou » d’un chat par rapport à son « sifflement ».
À l’avenir, ce modèle pourrait potentiellement conduire à des interfaces plus intuitives « basées sur l’imitation » pour les concepteurs sonores, à des personnages d’IA plus humains dans la réalité virtuelle et même à des méthodes pour aider les étudiants à apprendre de nouvelles langues.
Les co-auteurs principaux – MIT CSAIL Ph.D. les étudiants Kartik Chandra SM ’23 et Karima Ma, ainsi que le chercheur de premier cycle Matthew Caren, notent que les chercheurs en infographie reconnaissent depuis longtemps que le réalisme est rarement le but ultime de l’expression visuelle. Par exemple, une peinture abstraite ou un dessin au crayon d’un enfant peut être tout aussi expressif qu’une photographie.
« Au cours des dernières décennies, les progrès des algorithmes de dessin ont conduit à de nouveaux outils pour les artistes, à des progrès en matière d’IA et de vision par ordinateur, et même à une compréhension plus approfondie de la cognition humaine », note Chandra.
« De la même manière qu’un croquis est une représentation abstraite et non photoréaliste d’une image, notre méthode capture les manières abstraites et non phono-réalistes dont les humains expriment les sons qu’ils entendent. Cela nous renseigne sur le processus d’abstraction auditive. »
L’art de l’imitation, en trois parties
L’équipe a développé trois versions du modèle de plus en plus nuancées pour les comparer aux imitations vocales humaines. Premièrement, ils ont créé un modèle de base visant simplement à générer des imitations aussi similaires que possible aux sons du monde réel, mais ce modèle ne correspondait pas très bien au comportement humain.
Les chercheurs ont ensuite conçu un deuxième modèle « communicatif ». Selon Caren, ce modèle prend en compte ce qui distingue un son d’un auditeur. Par exemple, vous imiteriez probablement le bruit d’un bateau à moteur en imitant le grondement de son moteur, puisque c’est sa caractéristique auditive la plus distinctive, même si ce n’est pas l’aspect le plus fort du son (par rapport, par exemple, aux éclaboussures d’eau). Ce deuxième modèle a créé des imitations meilleures que la ligne de base, mais l’équipe a voulu l’améliorer encore plus.
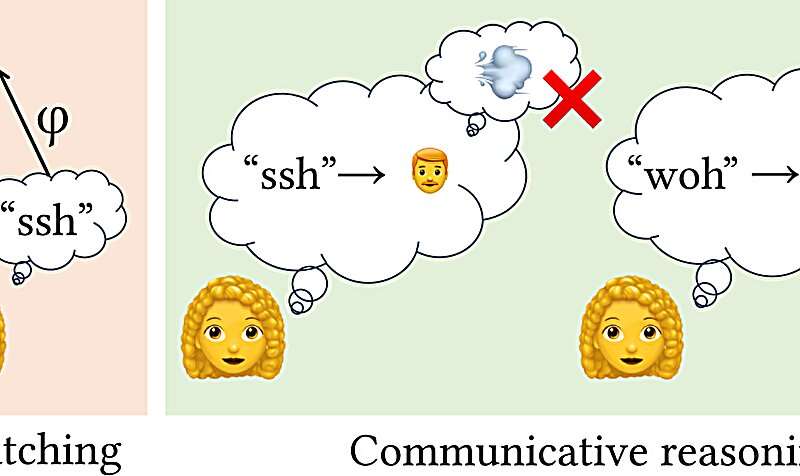
Pour aller plus loin dans leur méthode, les chercheurs ont ajouté une dernière couche de raisonnement au modèle. « Les imitations vocales peuvent avoir un son différent en fonction de l’effort que vous y consacrez. Il faut du temps et de l’énergie pour produire des sons parfaitement précis », explique Chandra.
Le modèle complet des chercheurs tient compte de cela en essayant d’éviter les énoncés très rapides, forts ou aigus ou graves, que les gens sont moins susceptibles d’utiliser dans une conversation. Le résultat : des imitations plus humaines qui correspondent étroitement à bon nombre des décisions que les humains prennent en imitant les mêmes sons.
Après avoir construit ce modèle, l’équipe a mené une expérience comportementale pour voir si les imitations vocales générées par l’IA ou par l’homme étaient perçues comme meilleures par les juges humains. Notamment, les participants à l’expérience ont favorisé le modèle d’IA 25 % du temps en général, et jusqu’à 75 % pour une imitation d’un bateau à moteur et 50 % pour une imitation d’un coup de feu.
Vers une technologie sonore plus expressive
Passionné par la technologie pour la musique et l’art, Caren estime que ce modèle pourrait aider les artistes à mieux communiquer les sons aux systèmes informatiques et aider les cinéastes et autres créateurs de contenu à générer des sons d’IA plus nuancés par rapport à un contexte spécifique. Cela pourrait également permettre à un musicien de rechercher rapidement une base de données sonores en imitant un bruit difficile à décrire, par exemple dans une invite textuelle.
En attendant, Caren, Chandra et Ma étudient les implications de leur modèle dans d’autres domaines, notamment le développement du langage, la façon dont les nourrissons apprennent à parler et même les comportements d’imitation chez les oiseaux comme les perroquets et les oiseaux chanteurs.
L’équipe a encore du travail à faire avec l’itération actuelle de son modèle : elle a du mal avec certaines consonnes, comme le « z », ce qui conduit à des impressions inexactes de certains sons, comme le bourdonnement des abeilles. Ils ne peuvent pas non plus reproduire la façon dont les humains imitent la parole, la musique ou les sons qui sont imités différemment selon les langues, comme un battement de cœur.
Robert Hawkins, professeur de linguistique à l’Université de Stanford, affirme que le langage est plein d’onomatopées et de mots qui imitent mais ne reproduisent pas complètement les choses qu’ils décrivent, comme le son « miaou » qui se rapproche très inexactement du son émis par les chats.
« Les processus qui nous font passer du son d’un vrai chat à un mot comme » miaou « en révèlent beaucoup sur l’interaction complexe entre la physiologie, le raisonnement social et la communication dans l’évolution du langage », explique Hawkins, qui n’a pas participé. dans la recherche CSAIL.
« Ce modèle représente une étape passionnante vers la formalisation et le test des théories de ces processus, démontrant que les contraintes physiques du conduit vocal humain et les pressions sociales de la communication sont nécessaires pour expliquer la distribution des imitations vocales. »