
Les chercheurs découvrent certaines des causes profondes
Lorsque vous avez une conversation aujourd'hui, remarquez les moments naturels où l'échange laisse la possibilité à l'autre personne d'intervenir. Si son timing n'est pas correct, elle peut être considérée comme trop agressive, trop timide ou tout simplement maladroite.
Le va-et-vient est l’élément social de l’échange d’informations qui se produit dans une conversation, et bien que les humains le fassent naturellement – à quelques exceptions près – les systèmes linguistiques de l’IA sont universellement mauvais dans ce domaine.
Les chercheurs en linguistique et en informatique de Tufts ont maintenant découvert certaines des causes profondes de ce déficit de compétences conversationnelles en IA et indiquent des moyens possibles d'en faire de meilleurs partenaires de conversation. Les résultats de leur étude seront présentés lors de la conférence Empirical Methods in Natural Language Processing (EMNLP 2024), qui se tiendra à Miami du 12 au 16 novembre, et seront publiés sur le arXiv serveur de préimpression.
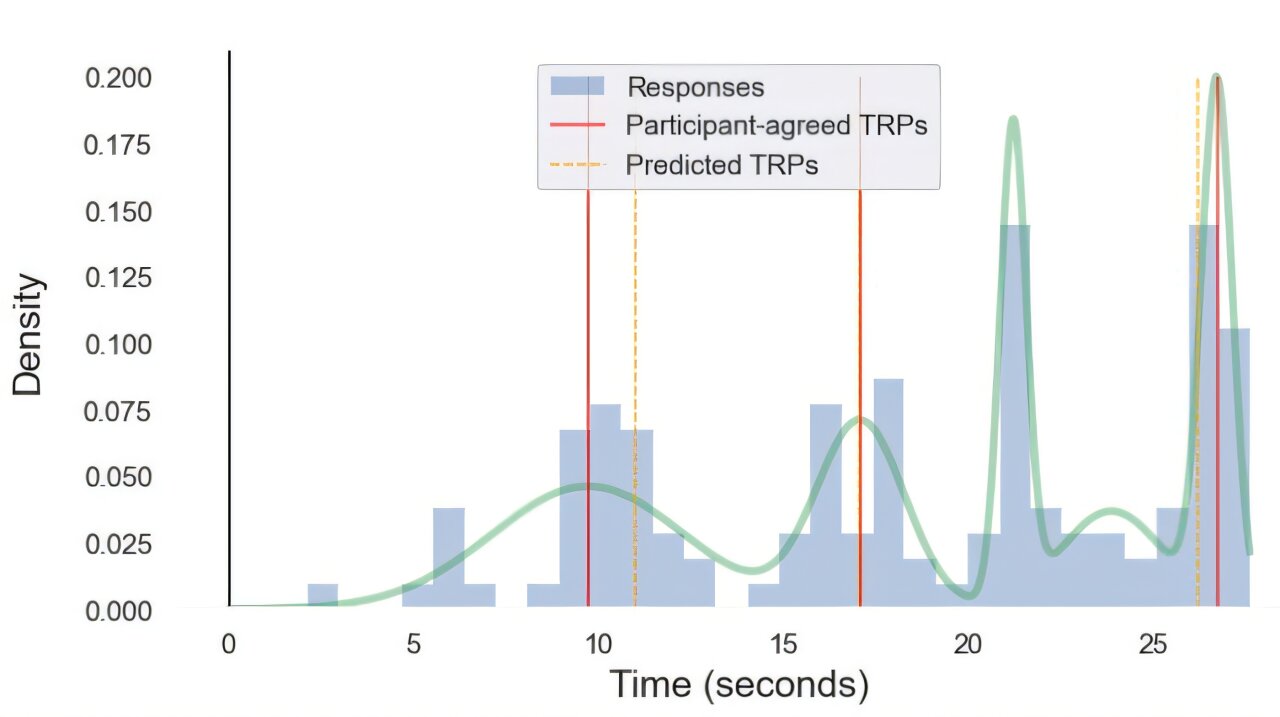
Lorsque les humains interagissent verbalement, la plupart du temps, ils évitent de parler simultanément, parlant et écoutant à tour de rôle. Chaque personne évalue de nombreux signaux d'entrée pour déterminer ce que les linguistes appellent des « lieux pertinents pour la transition » ou TRP. Les TRP se produisent souvent dans les conversations. Souvent, nous acceptons un laissez-passer lors d'un TRP et laissons l'orateur continuer. D’autres fois, nous utiliserons le TRP pour partager nos réflexions à notre tour.
JP de Ruiter, professeur de psychologie et d'informatique, explique que pendant longtemps on a pensé que les informations « paraverbales » contenues dans les conversations – les intonations, l'allongement des mots et des phrases, les pauses et certains signaux visuels – étaient les signaux les plus importants. pour identifier un TRP.
« Cela aide un peu », dit de Ruiter, « mais si vous supprimez les mots et donnez simplement aux gens la prosodie – la mélodie et le rythme de la parole qui ressort comme si vous parliez à travers une chaussette – ils ne peuvent plus détecter les TRP appropriés. »
Faites l’inverse et fournissez simplement le contenu linguistique dans un discours monotone, et les sujets de l’étude trouveront la plupart des mêmes TRP qu’ils trouveraient dans un discours naturel.
« Ce que nous savons maintenant, c'est que le signal le plus important pour discuter à tour de rôle est le contenu linguistique lui-même. Les pauses et autres signaux n'ont pas beaucoup d'importance », explique de Ruiter.
L'IA est excellente pour détecter des modèles de contenu, mais lorsque de Ruiter, l'étudiant diplômé Muhammad Umair et le professeur adjoint de recherche en informatique Vasanth Sarathy, EG20, ont testé des conversations transcrites par rapport à un grand modèle de langage d'IA, l'IA n'a pas été en mesure de détecter les TRP appropriés. avec n’importe où près de la capacité des humains.
La raison vient de la formation sur laquelle l’IA est formée. Les grands modèles linguistiques, y compris les plus avancés tels que ChatGPT, ont été formés sur un vaste ensemble de données de contenu écrit provenant d'Internet (entrées Wikipédia, groupes de discussion en ligne, sites Web d'entreprises, sites d'actualités) à peu près tout.
Ce qui manque dans cet ensemble de données, c'est une quantité significative de langage conversationnel parlé transcrit, qui n'est pas scripté, utilise un vocabulaire plus simple et des phrases plus courtes, et est structuré différemment du langage écrit. L’IA n’a pas été « élevée » sur la conversation, elle n’a donc pas la capacité de modéliser ou d’engager une conversation d’une manière plus naturelle et plus humaine.
Les chercheurs ont pensé qu'il pourrait être possible de prendre un modèle de langage étendu formé sur le contenu écrit et de l'affiner avec une formation supplémentaire sur un ensemble plus restreint de contenus conversationnels afin qu'il puisse s'engager plus naturellement dans une nouvelle conversation. Lorsqu’ils ont essayé cela, ils ont constaté qu’il y avait encore certaines limites à la reproduction d’une conversation de type humain.
Les chercheurs préviennent qu’il pourrait y avoir un obstacle fondamental à la conduite d’une conversation naturelle par l’IA. « Nous supposons que ces grands modèles linguistiques peuvent comprendre correctement le contenu. Ce n'est peut-être pas le cas », explique Sarathy. « Ils prédisent le mot suivant sur la base de corrélations statistiques superficielles, mais prendre leur tour implique de s'inspirer du contexte beaucoup plus profondément dans la conversation. »
« Il est possible que ces limitations puissent être surmontées en pré-entraînant de grands modèles de langage sur un plus grand corps de langage parlé naturellement », explique Umair, dont le doctorat. la recherche se concentre sur les interactions homme-robot et sur qui est l’auteur principal des études.
« Bien que nous ayons publié un nouvel ensemble de données de formation qui aide l'IA à identifier les opportunités de parole dans un dialogue naturel, la collecte de ces données à une échelle requise pour former les modèles d'IA actuels reste un défi important », a-t-il déclaré. « Il n'y a tout simplement pas autant d'enregistrements et de transcriptions de conversations disponibles que de contenu écrit sur Internet. »