
Une équipe de recherche conçoit un algorithme de protection de la vie privée pour une meilleure communication sans fil
Dans le monde d’aujourd’hui de plus en plus interconnecté, une communication de haute qualité est devenue plus vitale que jamais. Pour y parvenir, il est essentiel d’estimer avec précision l’état dynamique des canaux de communication. Récemment, une équipe de recherche commune a conçu un nouvel algorithme offrant une précision d’estimation de haut niveau et une protection de la vie privée avec de faibles coûts de calcul et de communication. Cette recherche a été publiée dans Informatique intelligente.
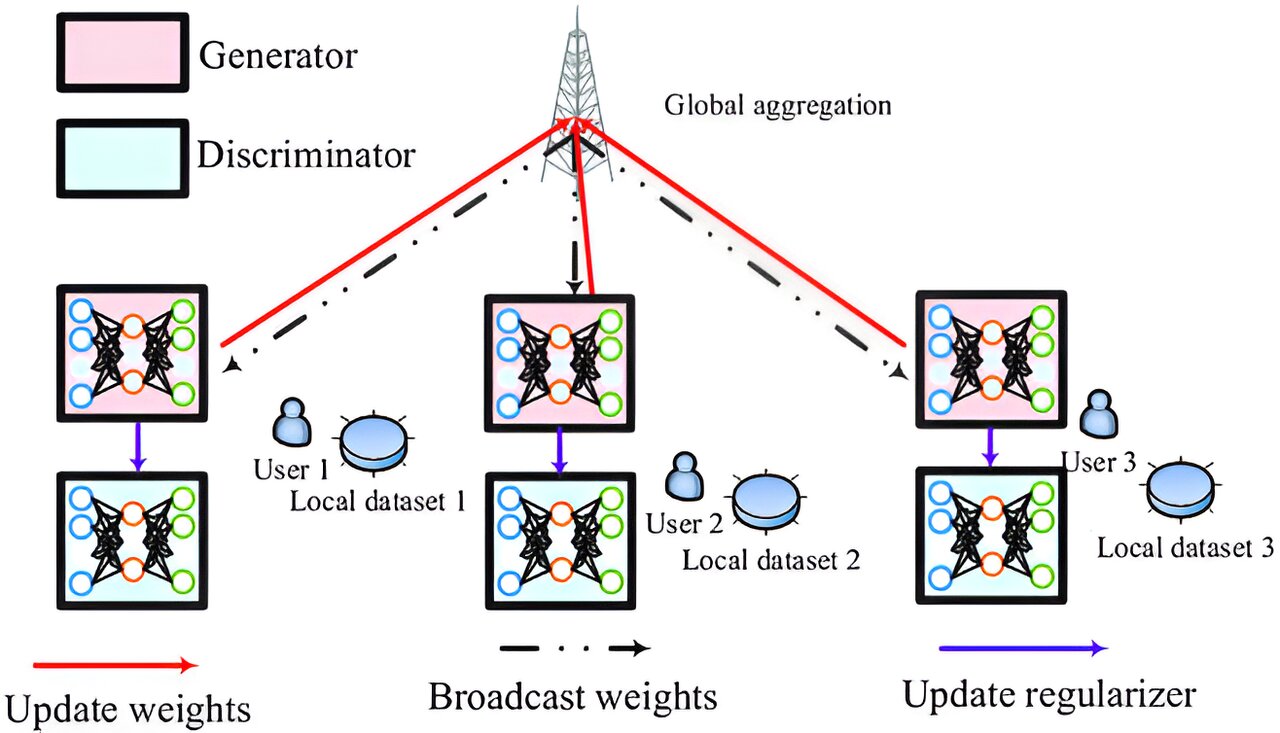
Ce nouvel algorithme utilise un modèle d’apprentissage en profondeur spécialement conçu pour une estimation précise et un cadre d’apprentissage fédéré pour entraîner le modèle tout en garantissant la sécurité des données utilisateur et une faible surcharge. Il comprend également un programme de motivation des utilisateurs pour tirer le meilleur parti des ressources informatiques.
L’équipe a testé l’algorithme dans un réseau de communication sans fil en utilisant des ensembles de données d’utilisateurs locaux et des ensembles de données d’environnement réalistes. Le test sur les ensembles de données d’utilisateurs locaux a démontré que leur méthode est plus précise dans l’estimation des informations sur l’état du canal par rapport à certains algorithmes traditionnels et d’apprentissage profond dans différents rapports signal/bruit, fréquences pilotes et autres conditions.
Le test d’environnement réaliste a en outre prouvé l’efficacité de l’algorithme. Les données de canal utilisées dans le test proviennent d’un ensemble de données ouvert sur les communications mobiles et incluent des scénarios clairsemés et denses ; le scénario clairsemé contient 10 000 cartes, chacune contenant cinq emplacements de stations de base et 30 emplacements d’utilisateurs, et le scénario dense contient 100 cartes, chacune contenant un emplacement de stations de base et 10 000 emplacements d’utilisateurs. Tous les utilisateurs sont supposés immobiles tout au long du processus.
Les résultats montrent que l’algorithme surpasse trois modèles de pointe dans les scénarios clairsemés et denses, et que l’écart de performances est plus large dans le scénario clairsemé où les conditions sont plus variables et complexes. Cela signifie que le modèle formé via l’apprentissage fédéré et avec un niveau plus élevé de participation des utilisateurs est plus robuste, adaptable et évolutif que les modèles de référence, qui ont été formés de manière centralisée.
Dans un cadre d’apprentissage fédéré, les ressources utilisées pour la formation sont celles des appareils locaux, qui échangent des paramètres plutôt que des données brutes avec le serveur central. Cela réduit les coûts de calcul et de communication, protège la confidentialité des données des utilisateurs et convient aux grands réseaux de communication complexes, et complète ainsi parfaitement les modèles d’apprentissage en profondeur axés sur la précision et moins flexibles, comme, dans ce cas, un réseau adverse génératif.
Un réseau antagoniste génératif typique se compose d’un générateur et d’un discriminateur : le premier crée des échantillons pour se rapprocher des données du monde réel, et le second défie les échantillons pour obtenir de meilleurs résultats. L’équipe a conçu sa version dans un réseau en forme de double U pour éviter la perte d’informations lors de l’échantillonnage et a ajouté une fonction de régularisation au niveau du discriminateur pour une cohérence et une stabilité accrues.
L’équipe a souligné que leur algorithme présente certaines limites, notamment de nombreux paramètres de modèle et le recours à des données étiquetées. La compression du modèle et son entraînement avec des approches non supervisées sont des orientations possibles pour les travaux futurs. À l’avenir, ils prévoient d’explorer l’apprentissage fédéré dans des réseaux dynamiques et diversifiés où chaque appareil possède des ressources différentes pour effectuer la vérification embarquée et la sélection des clients.