
ChatGPT a lu presque tout Internet. Cela n’a pas résolu ses problèmes de diversité
Les modèles de langage d’IA sont en plein essor. Le favori actuel est ChatGPT, qui peut tout faire, de passer un examen du barreau à la création d’une politique RH en passant par l’écriture d’un scénario de film.
Mais lui et d’autres modèles ne peuvent toujours pas raisonner comme un humain. Dans cette séance de questions-réponses, le Dr Vered Shwartz, professeur adjoint au département d’informatique de l’UBC, et l’étudiante à la maîtrise Mehar Bhatia expliquent pourquoi le raisonnement pourrait être la prochaine étape de l’IA et pourquoi il est important d’entraîner ces modèles à l’aide de divers ensembles de données provenant de différentes cultures.
Qu’est-ce que le « raisonnement » pour l’IA ?
Shwartz : Les grands modèles de langage comme ChatGPT apprennent en lisant des millions de documents, essentiellement sur Internet dans son intégralité, et en reconnaissant des modèles pour produire des informations. Cela signifie qu’ils ne peuvent fournir que des informations sur des éléments documentés sur Internet. Les humains, en revanche, sont capables de raisonner. Nous utilisons la logique et le bon sens pour trouver un sens au-delà de ce qui est explicitement dit.
Bhatia : Nous apprenons la capacité de raisonner dès la naissance. Par exemple, nous savons qu’il ne faut pas allumer le mixeur à 2 heures du matin car cela réveillerait tout le monde. On ne nous apprend pas cela, mais c’est quelque chose que l’on comprend en fonction de la situation, de son environnement et de son entourage. Dans un avenir proche, les modèles d’IA prendront en charge bon nombre de nos tâches. Nous ne pouvons pas coder en dur toutes les règles de bon sens dans ces robots, nous voulons donc qu’ils comprennent la bonne chose à faire dans un contexte spécifique.
Shwartz : S’appuyer sur un raisonnement de bon sens pour les modèles actuels comme ChatGPT les aiderait à fournir des réponses plus précises et ainsi à créer des outils plus puissants que les humains pourraient utiliser. Les modèles d’IA actuels font preuve d’une certaine forme de raisonnement fondé sur le bon sens. Par exemple, si vous interrogez la dernière version de ChatGPT sur la tarte à la boue d’un enfant et d’un adulte, elle peut correctement différencier un dessert d’un visage plein de saleté en fonction du contexte.
Où les modèles de langage d’IA échouent-ils ?
Shwartz : Le raisonnement de bon sens dans les modèles d’IA est loin d’être parfait. Nous n’y parviendrons que si nous nous entraînons sur des quantités massives de données. Les humains devront encore intervenir et former les modèles, notamment en fournissant les bonnes données.
Par exemple, nous savons que les textes anglais sur le Web proviennent en grande partie d’Amérique du Nord, de sorte que les modèles de langue anglaise, qui sont les plus couramment utilisés, ont tendance à avoir un biais nord-américain et risquent soit de ne pas connaître les concepts d’autres cultures, soit de ne pas connaître les concepts d’autres cultures. de perpétuer les stéréotypes.
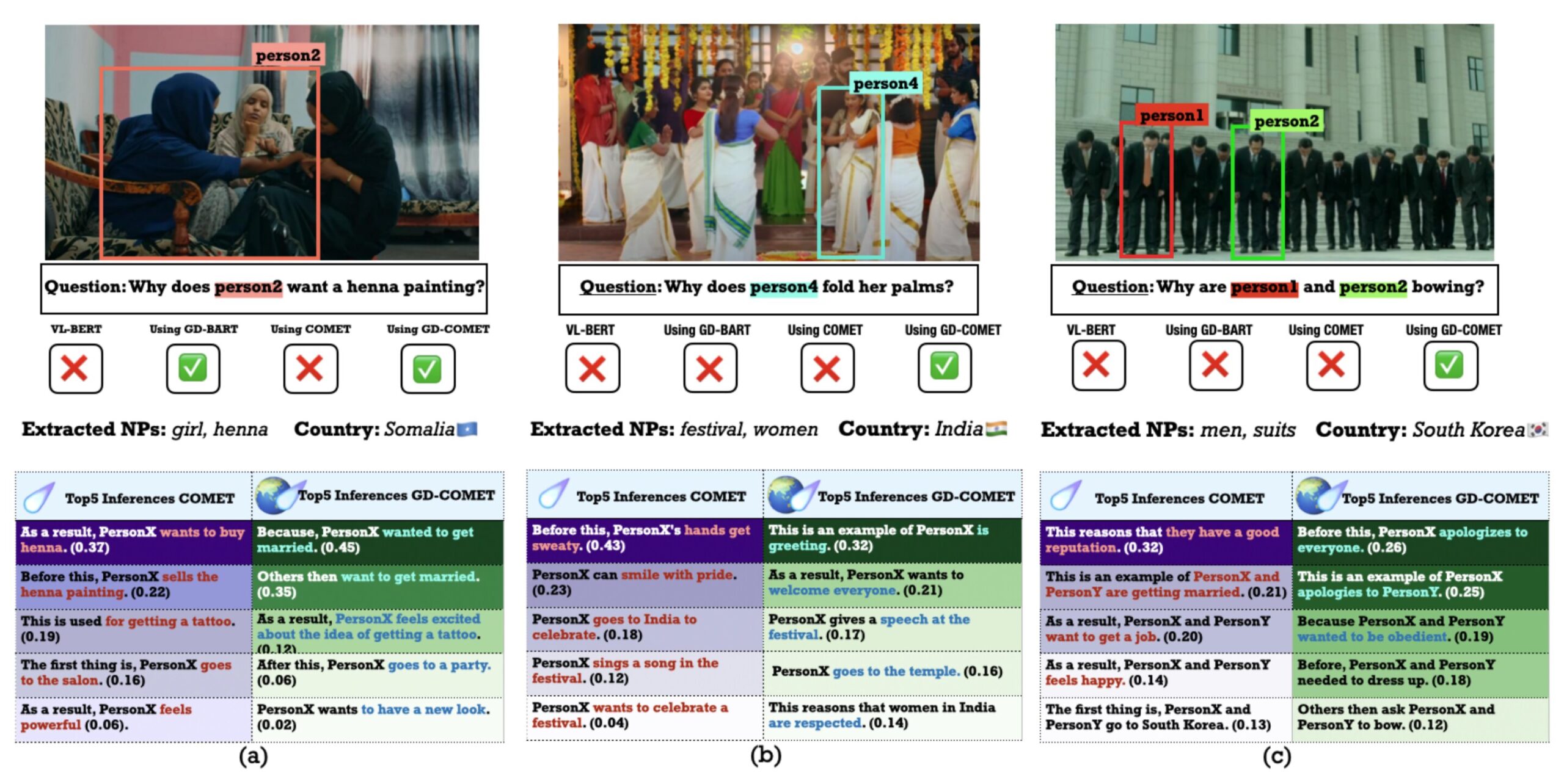
Dans un article récent (publié dans Actes de la conférence 2023 sur les méthodes empiriques dans le traitement du langage naturel), nous avons constaté que la formation d’un modèle de raisonnement de bon sens sur des données provenant de différentes cultures, notamment l’Inde, le Nigeria et la Corée du Sud, aboutissait à des réponses plus précises et culturellement informées.
Bhatia : Un exemple consistait à montrer au modèle l’image d’une femme en Somalie se faisant tatouer au henné et à lui demander pourquoi elle pourrait vouloir cela. Lorsqu’il a été formé avec des données culturellement diverses, le modèle a suggéré à juste titre qu’elle était sur le point de se marier, alors qu’auparavant, il disait qu’elle voulait acheter du henné.
Shwartz : Nous avons également trouvé des exemples de ChatGPT manquant de sensibilisation culturelle. Lorsqu’on lui a donné une situation hypothétique dans laquelle un couple donnerait un pourboire de quatre pour cent dans un restaurant en Espagne, le mannequin a suggéré qu’ils n’étaient peut-être pas satisfaits du service. Cela suppose que la culture nord-américaine du pourboire s’applique en Espagne alors qu’en réalité, le pourboire n’est pas courant dans le pays, et un pourboire de 4 % signifie probablement un service exceptionnel.
Pourquoi devons-nous veiller à ce que l’IA soit plus inclusive ?
Shwartz : Les modèles linguistiques sont omniprésents. Si ces modèles assument l’ensemble des valeurs et des normes associées à la culture occidentale ou nord-américaine, leurs informations sur et concernant les personnes d’autres cultures pourraient être inexactes et discriminatoires. Une autre préoccupation est que les personnes d’horizons divers utilisant des produits basés sur des modèles anglais devraient adapter leurs entrées aux normes nord-américaines, sinon elles pourraient obtenir des performances sous-optimales.
Bhatia : Nous voulons que ces outils soient accessibles à tous, et pas seulement à un groupe de personnes. Le Canada est un pays culturellement diversifié, et nous devons nous assurer que les outils d’IA qui alimentent nos vies ne reflètent pas une seule culture et ses normes. Nos recherches en cours visent à favoriser l’inclusion, la diversité et la sensibilité culturelle dans le développement et le déploiement des technologies d’IA.