
Voir les images 3D à travers les yeux de l’IA
La technologie de reconnaissance d’images a parcouru un long chemin depuis 2012, lorsqu’un groupe d’informaticiens de l’Université de Toronto a créé un réseau neuronal convolutif (CNN) – surnommé « AlexNet » en l’honneur de son créateur Alex Krizhevsky – qui identifiait correctement les images bien mieux que d’autres. Ses découvertes ont propulsé l’utilisation réussie des CNN dans des domaines connexes tels que l’analyse vidéo et la reconnaissance de formes, et les chercheurs se concentrent désormais sur les réseaux d’apprentissage profond 3D.
Contrairement aux images 2D identifiées avec compétence par AlexNet, les données 3D représentent un défi différent. Alors que l’élément de base des images 2D basées sur une grille est le pixel, et que le pixel en haut à gauche est toujours le premier pixel avec tous les autres pixels ordonnés par rapport à lui, ce n’est pas le cas pour les données 3D. Avec trois dimensions à prendre en compte, généralement désignées par les axes x, y et z, les CNN 3D traitent des « points » 3D au lieu de pixels. La collection de ces points constitue un nuage de points 3D qui est le résultat direct de nombreux scanners 3D et la représentation de données 3D la plus populaire.
« Les nuages de points 3D ne sont pas bien structurés et les points 3D sont dispersés, clairsemés et désordonnés », explique Zhang Zhiyuan, professeur adjoint d’informatique à la SMU School of Computing and Information Systems. « Ainsi, les réseaux de neurones traditionnels comme les CNN, qui peuvent bien fonctionner sur des images 2D bien structurées, ne peuvent pas s’appliquer directement sur des nuages de points 3D sans ordre, et nous devons concevoir de nouveaux opérateurs de convolution pour les nuages de points 3D. »
Château sur un nuage (de points 3D)
Cette absence de premier point 3D, contrairement au premier pixel d’une image 2D, est appelée « ambiguïté de l’ordre des points ». Même si les données 3D ont été introduites dans les CNN avec un certain succès et une certaine précision d’identification, une architecture de réseau complexe est nécessaire et la vitesse de formation est faible. Ils ne sont pas non plus invariants par rotation, c’est-à-dire capables d’identifier deux objets comme des versions pivotées l’un de l’autre.
« Les réseaux neuronaux existants ne peuvent reconnaître qu’un objet 3D se trouvant dans une pose similaire contenue dans les données d’entraînement », explique le professeur Zhang. « Prenons par exemple la reconnaissance humaine 3D. Pendant la phase de formation, tous les modèles humains 3D sont en position debout, tandis que dans l’application réelle (pendant la phase de test), le réseau reçoit le même modèle humain mais en position couchée. Les réseaux neuronaux bien entraînés ne peuvent pas le reconnaître car ils n’ont pas vu une telle pose.
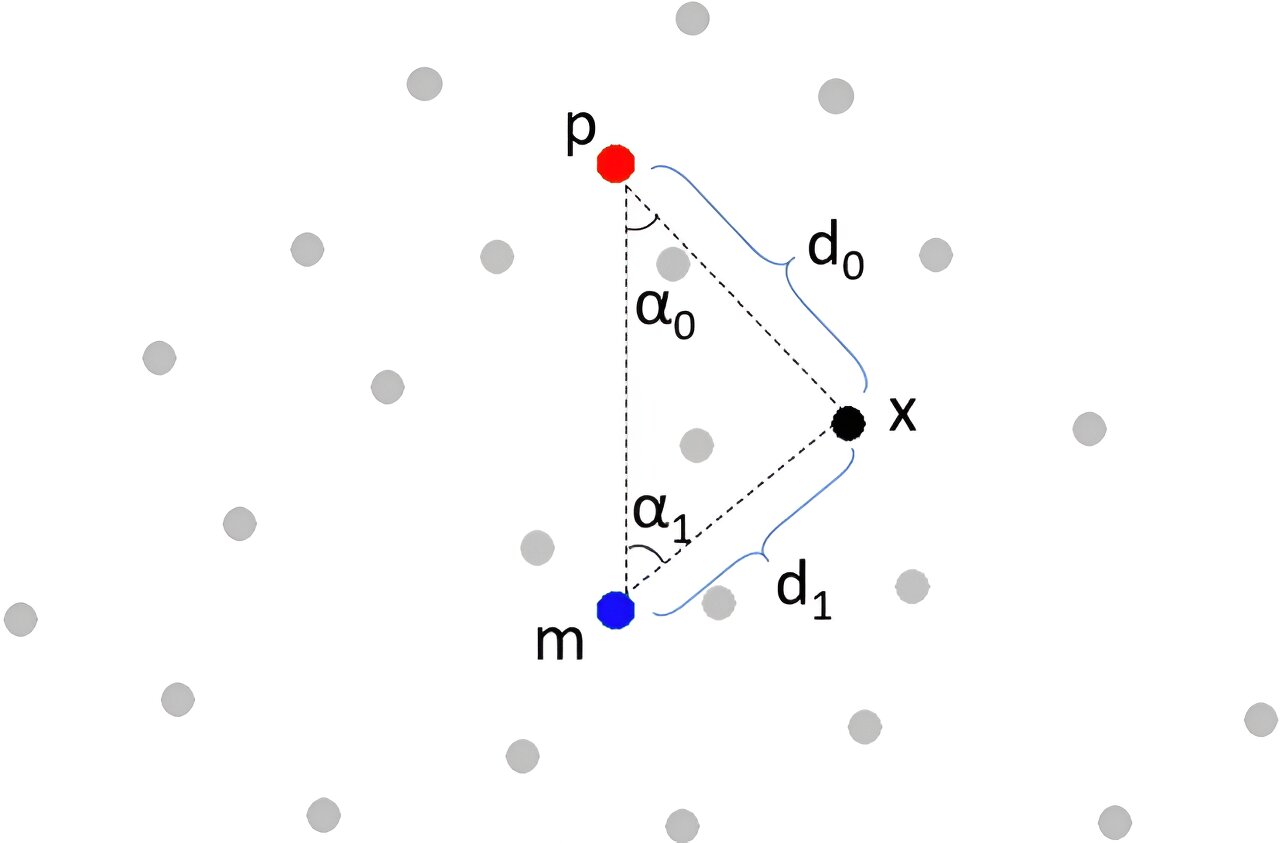
« Ainsi, les réseaux invariants en rotation sont importants car ils peuvent être plus généralisés et efficaces dans des applications réelles. Nous ne pouvons pas garantir que l’objet 3D donné est dans la même pose que lors de la phase de formation. Cela est particulièrement vrai pour les données 3D car elles ont plus de liberté de rotation que les données 2D. Ce problème est résolu par l’article du professeur Zhang, « RIConv++: Effective Rotation Invariant Convolutions for 3D Point Clouds ». RIConv++ obtient l’invariance de rotation en concevant des fonctionnalités informatives invariantes de rotation codant les angles et les longueurs entre les points 3D.
L’opération de convolution, qui consiste essentiellement à traiter des données numériques en images compréhensibles pour les humains, et la résolution de l’ambiguïté de l’ordre des points constituent l’essentiel de l’article du professeur Zhang, « ShellNet: Efficient Point Cloud Convolutional Neural Networks using Concentric Shell Statistics », publié dans le Journal international de vision par ordinateur. ShellNet, le CNN détaillé par le professeur Zhang dans son article, inclut ShellConv, un programme qui convertit les données 3D en structures de coque et effectue une convolution 1D (monodimensionnelle).
« C’est très efficace car seule une convolution 1D est nécessaire », explique le professeur Zhang, soulignant comment cela accélère la formation. « ShellConv atteint non seulement l’efficacité, mais il résout également le problème du désordre de manière très élégante. Il convertit l’ensemble de points sans ordre en structures de coque et crée l’ordre de la coque interne à la coque externe. »
Les intérêts de recherche du professeur Zhang englobent la programmation orientée objet ainsi que l’intelligence artificielle, mais cet article spécifique aura des implications significatives dans les domaines de la conduite autonome, de la navigation robotisée et des véhicules aériens sans pilote (UAV) qui nécessitent une perception précise et efficace de l’environnement 3D, y compris les objets 3D. reconnaissance et compréhension de la scène 3D.
Il ajoute : « De nos jours, les chercheurs se concentrent principalement sur la façon d’améliorer la précision en concevant des réseaux complexes qui sont difficiles à exécuter sur des appareils mobiles intelligents comme les robots et les drones. Pour de tels appareils, les réseaux légers sont préférés. Ainsi, ShellConv et ShellNet changent la recherche. concentrez-vous sur les applications réelles et les techniques efficaces d’apprentissage en profondeur 3D.